Documentation Index
Fetch the complete documentation index at: https://docs.getcollate.io/llms.txt
Use this file to discover all available pages before exploring further.
Getting Started: Day 1
Get started with your Collate service in just few simple steps:- Set up a Data Connector: Connect your data sources to begin collecting metadata.
- Ingest Metadata: Run the metadata ingestion to gather and push data insights.
- Invite Users: Add team members to collaborate and manage metadata together.
- Explore the Features: Dive into Collate’s rich feature set to unlock the full potential of your data.
Requirements
You should receive your initial Collate credentials from Collate support, or from your existing Collate admin. For any questions, please contact support@getcollate.io The following steps will provide initial set up information, with links to more detailed documentation.Step 1: Set up a Data Connector
Once you’re able to login to your Collate instance, set up a data connector to start bringing metadata into Collate. There are 90+ turnkey connectors to various services: data warehouses, data lakes, databases, dashboards, messaging services, pipelines, ML models, storage services, and other Metadata Services. Connections to custom data sources can also be created via API. There’s two options on how to set up a data connector:- Run the connector in Collate SaaS: In this scenario, you’ll get an IP when you add the service. You need to give access to this IP in your data sources.
Run the connector in Collate SaaS
Guide to start ingesting metadata seamlessly from your data sources.
- Run the connector in your infrastructure or laptop: The hybrid model offers organizations the flexibility to run metadata ingestion components within their own infrastructure. This approach ensures that Collate’s managed service doesn’t require direct access to the underlying data. Instead, only the metadata is collected locally and securely transmitted to our SaaS platform, maintaining data privacy and security while still enabling robust metadata management. You can read more about how to extract metadata in these cases here.
Step 2: Ingest Metadata
Once the connector has been added, set up a metadata ingestion pipeline to bring in the metadata into Collate at a regular schedule.- Go to Settings > Services > Databases and click on the service you have added. Navigate to the Ingestion tab to Add Metadata Ingestion.
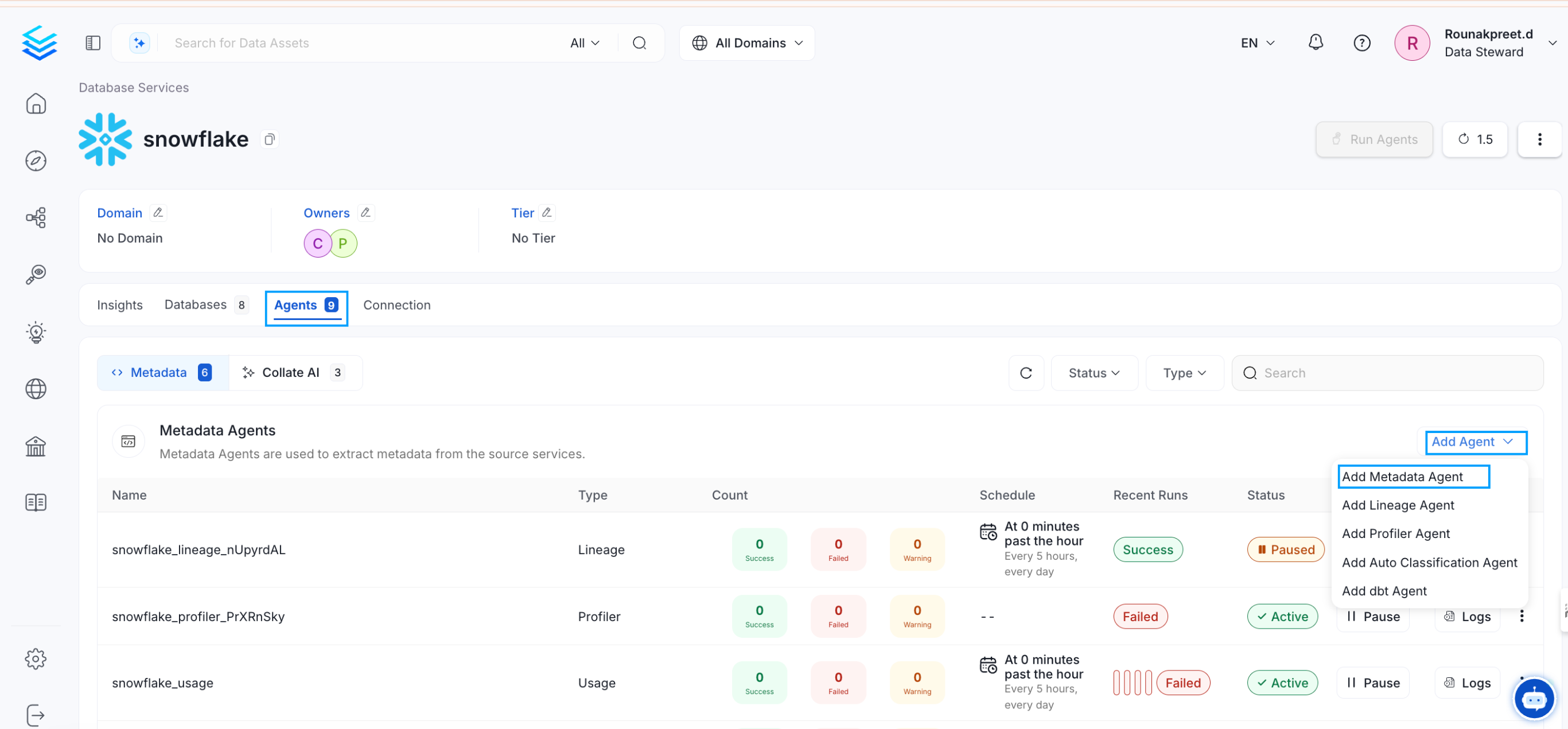
- Make any necessary configuration changes or filters for the ingestion, with documentation available in the side panel.
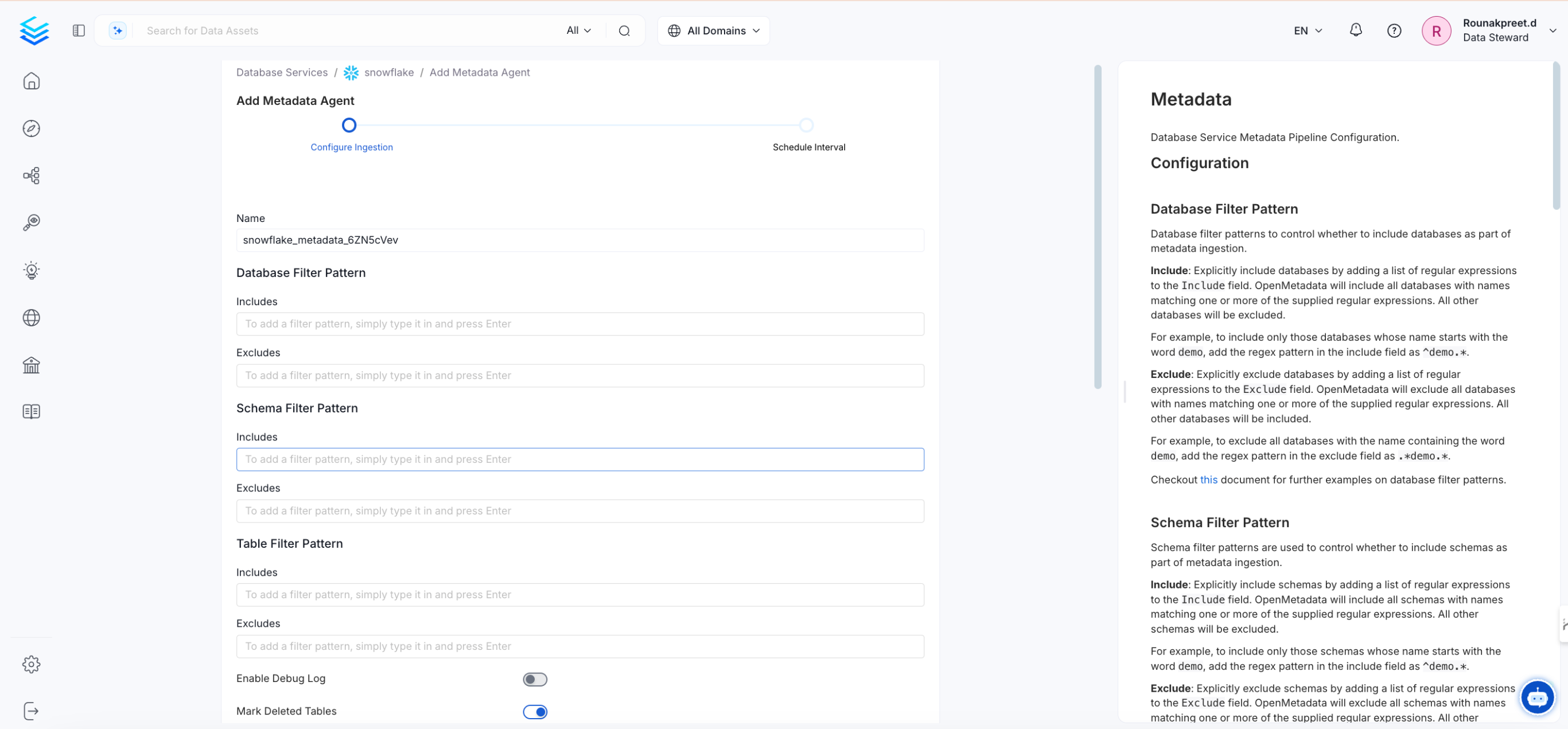
- Schedule the pipeline to ingest metadata regularly.
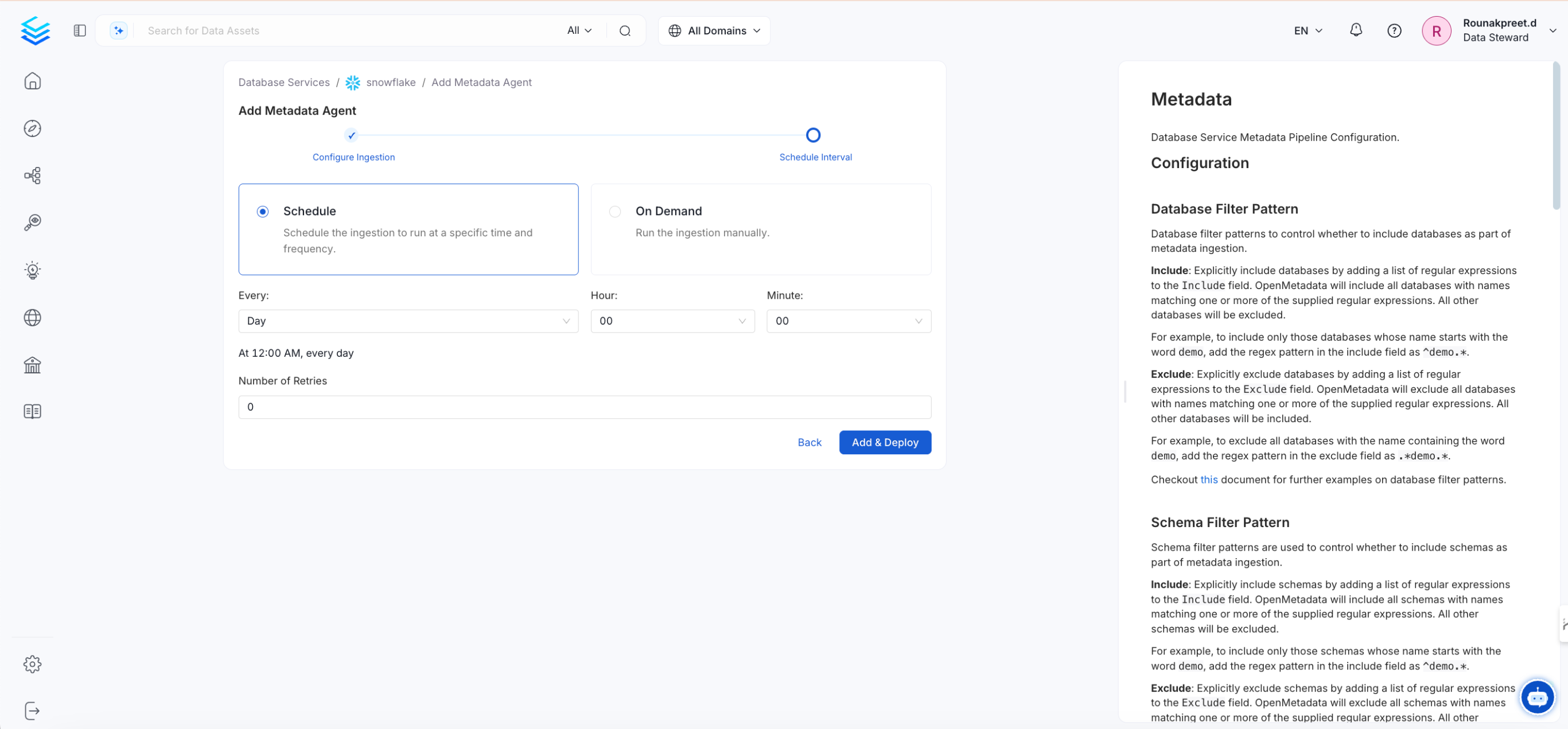
- Once scheduled, you can also set up additional ingestion pipelines to bring in lineage, profiler, or dbt information.
- Once the metadata ingestion has been completed, you can see the available data assets under Explore in the main menu.
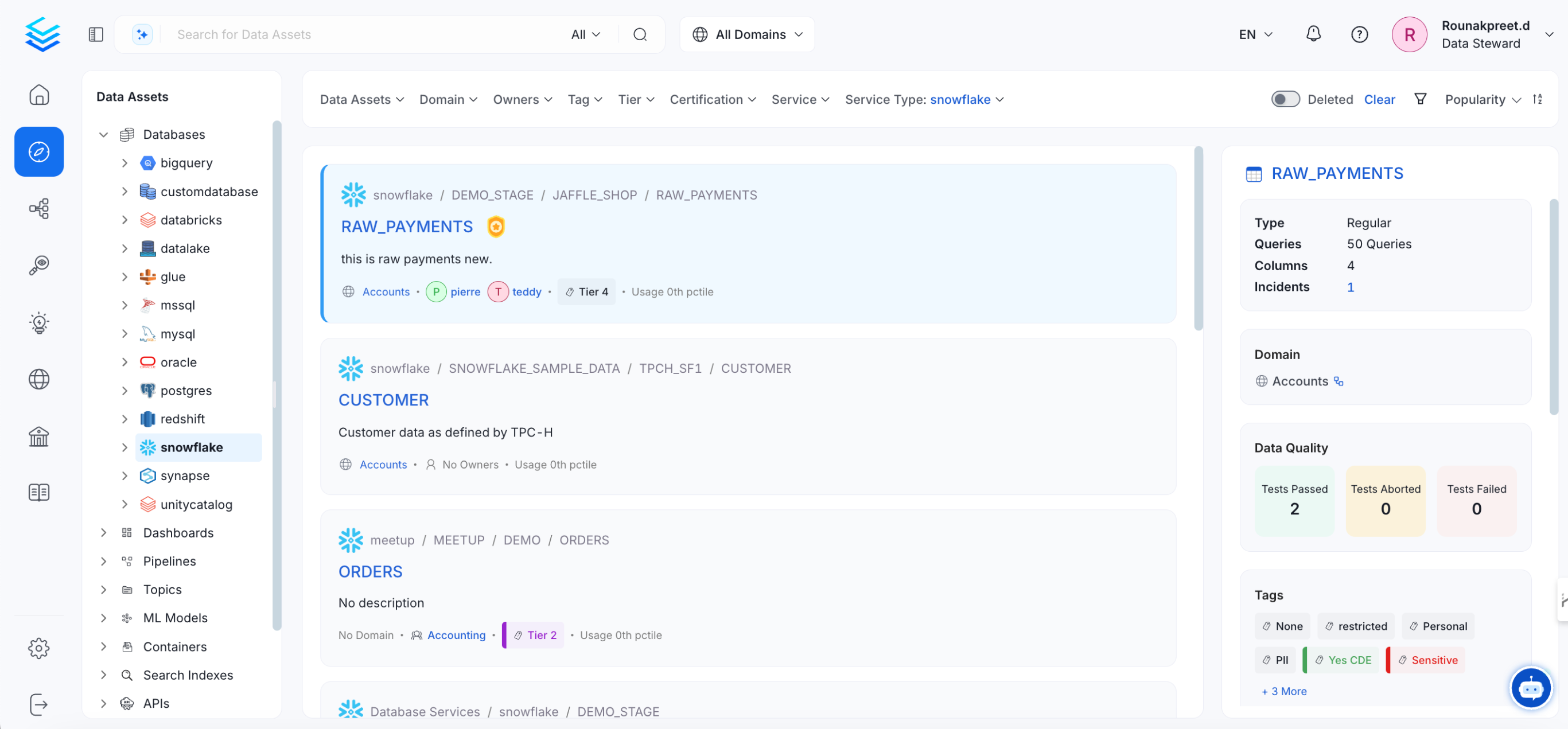
- You can repeat these steps to ingest metadata from other data sources.
Step 3: Invite Users
Once the metadata is ingested into the platform, you can invite users to collaborate on the data and assign different roles.- Navigate to Settings > Team & User Management > Users.
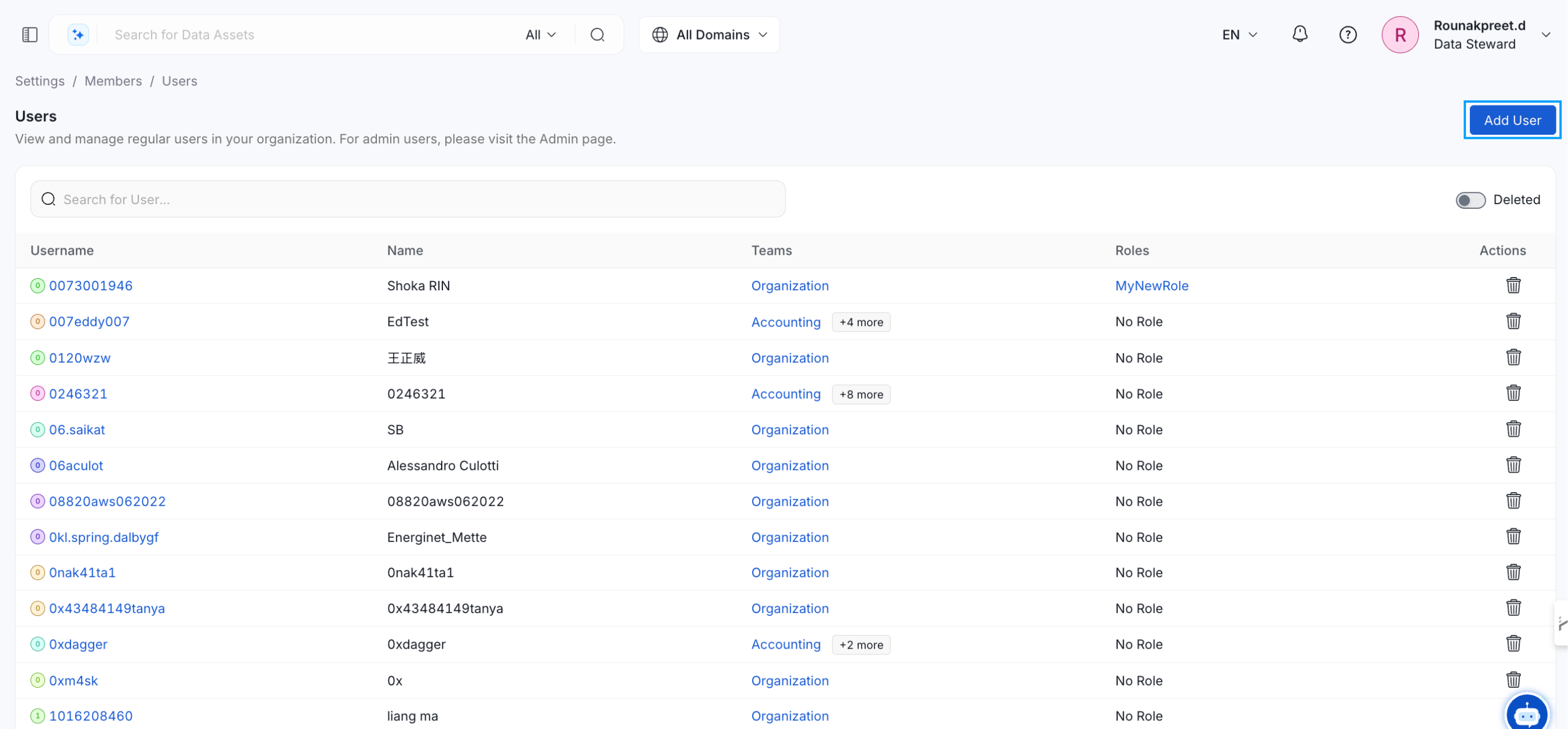
- Click on Add User, and enter their email and other details to provide access to the platform.
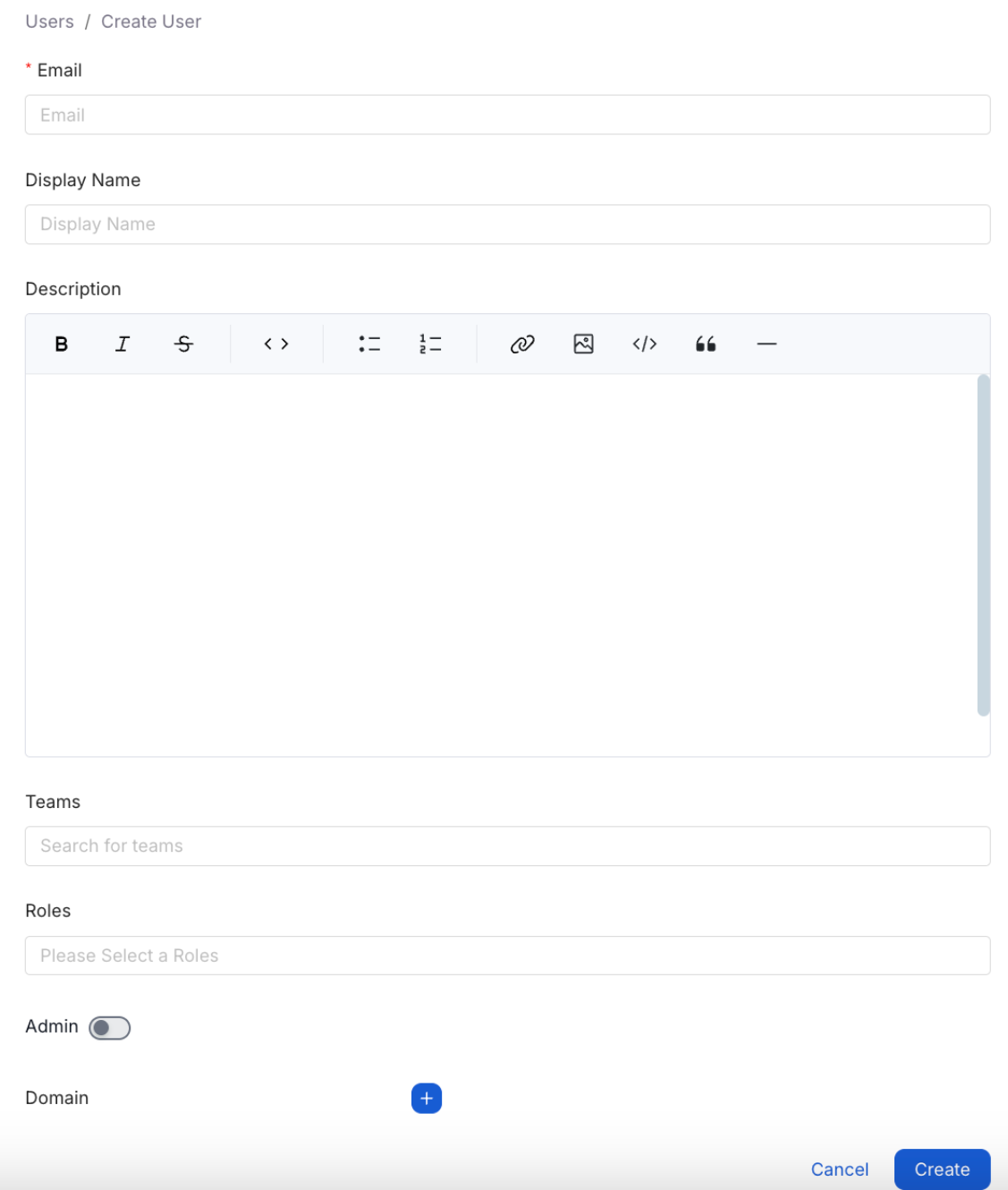
- You can organize users into different Teams, as well as assign them to different Roles.
- Users will inherit the access defined for their assigned Teams and Roles.
- Admin access can also be granted. Admins will have access to all settings and can invite other users.
- New users will receive an email invitation to set up their account.
Step 4: Explore Features of Collate
Collate provides a comprehensive solution for data teams to break down silos, securely share data assets across various sources, foster collaboration around trusted data, and establish a documentation-first data culture within the organization.Data Discovery
Discover the right data assets to make timely business decisions.
Data Collaboration
Foster data team collaboration to enhance data understanding.
Data Quality & Observability
Trust your data with quality tests & monitor the health of your data systems.
Data Lineage
Trace the path of data across tables, pipelines, and dashboards.
Data Insights
Define KPIs and set goals to proactively hone the data culture of your company.
Data Governance
Enhance your data platform governance using Collate.
Deep Dive into Collate: Guides for Admins and Data Users
Admin Guide
Admin users can get started with Collate with just three quick and easy steps & know-it-all with the advanced guides.
Guide for Data Users
Get to know the basics of Collate and about the data assets that you can explore in the all-in-one platform.
- You can check out the advanced guide to roles and policies to fine-tune role or team access to data.
- Trace your data flow with column-level lineage graphs to understand where your data comes from, how it is used, and how it is managed.
- Build no-code data quality tests to ensure its technical and business quality, and set up an alert for any test case failures to be quickly notified of critical data issues.
- Write Knowledge Center articles associated with data assets to document key information for your team, such as technical details, business context, and best practices.
- Review the different Data Insights Reports on Data Assets, App Analytics, KPIs, and Cost Analysis to understand the health, utilization, and costs of your data estate.
- Build no-code workflows with Metadata Automations to add attributes like owners, tiers, domains, descriptions, glossary terms, and more to data assets, as well as propagate them using column-level lineage for more automated data management.