What are Tiers
Tiering is an important concept of data classification in Collate. Tiers should be based on the importance of data. Using Tiers, data producers or owners can define the importance of data to an organization. In Collate, Tiers are System Classification tags and can be accessed from Govern > Classification > Tier.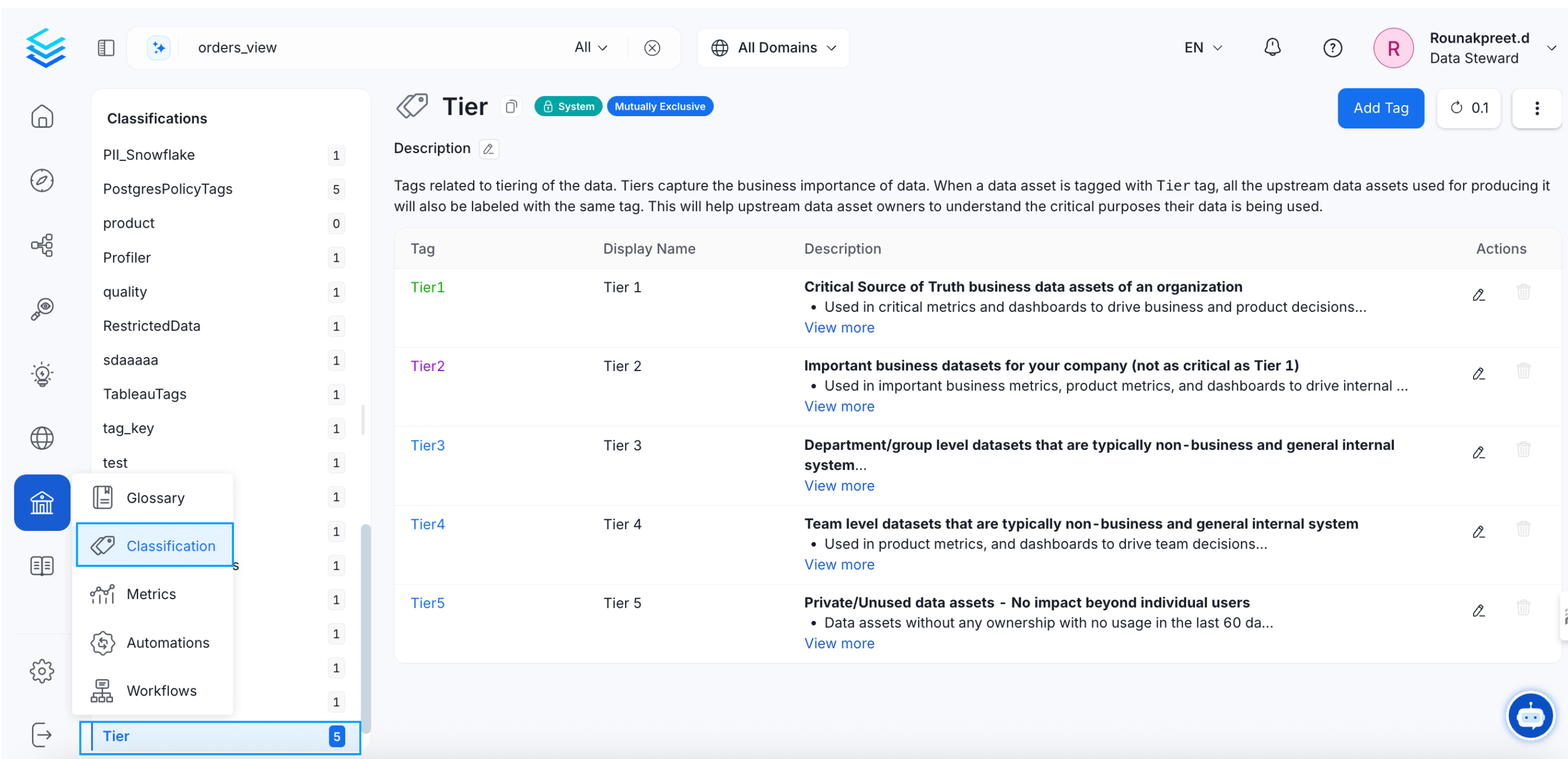
How to Add Tiers
From the Explore page, select a data asset and click on the edit icon for Tier. Select the appropriate tier. Clicking on the arrow next to the tier will provide a description of the tier.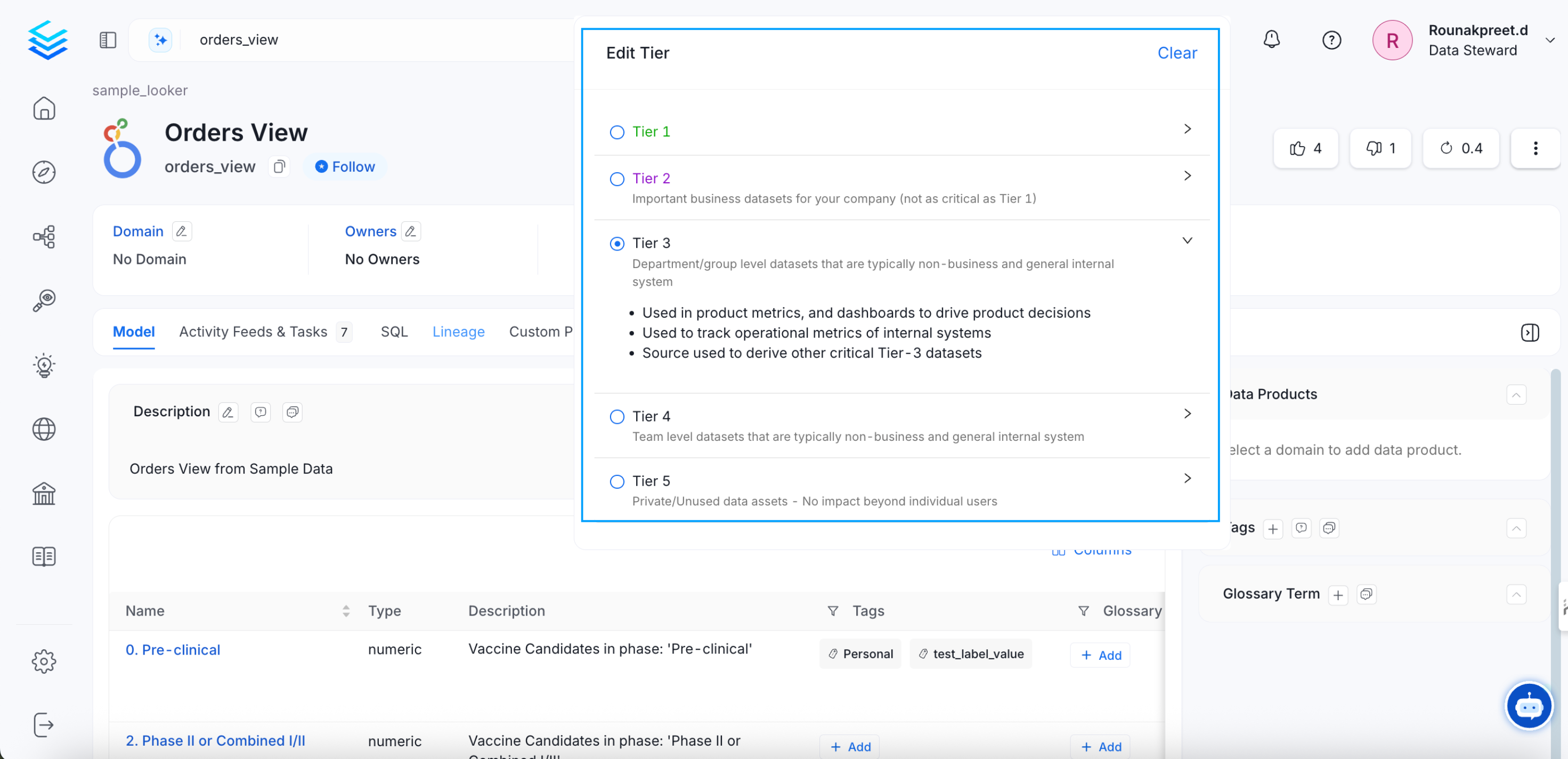
Best Practices for Classification
Here are the Best Practices around Classification.