dbt Workflow
Run in Collate SaaS or BYOC
Configure the dbt Workflow.
Run in Collate Hybrid SaaS
Configure the dbt Workflow from the CLI.
Auto Ingest dbt Artifacts (dbt-core)
Configure the auto dbt ingestion for dbt-core.
dbt Integration
Requirements
Collate supports ingestion from both dbt Core and dbt Cloud.The requirements vary depending on how dbt is deployed and executed.
Why We Need dbt Artifacts
To bring your dbt project into Collate, we need to read the metadata that dbt generates about your transformations. dbt automatically creates JSON files (called “artifacts”) whenever you run commands likedbt run, dbt test, or dbt docs generate.
These artifacts allow Collate to:
- Build lineage graphs — See how your models connect to sources and each other
- Sync documentation — Keep table and column descriptions in sync with your dbt project
- Track data quality — Monitor test results and show pass/fail status
- Import metadata — Bring over tags, ownership, domains, and custom properties
Understanding dbt Artifact Files
dbt generates JSON files in thetarget/ directory. Here’s what each file provides:
manifest.json (Required)
The manifest is the heart of dbt metadata. This file is required for the integration to work. What it contains:- Model definitions and SQL code
ref()andsource()dependencies for lineage- Descriptions from
schema.ymlfiles - dbt tags and meta properties
- Test configurations
- Column definitions
- Creates Data Model entities linked to your tables
- Builds lineage graphs showing data flow between models
- Syncs table and column descriptions
- Creates classification tags
- Assigns ownership and domains
- Creates test cases for data quality monitoring
dbt run, dbt build, dbt compile)
catalog.json (Recommended)
The catalog provides database-level details that the manifest doesn’t have. What it contains:- Actual column data types from the database
- Database-level ownership information
- Column ordering as it exists in the database
- Statistics about tables and columns
- Provides accurate column data types (more reliable than schema.yml declarations)
- Fallback owner information if not specified in meta properties
- Maintains column position from your database
dbt docs generate
Without catalog.json, you’ll still get lineage and model information, but column types will only include what’s declared in your
schema.yml files.run_results.json (Recommended)
Run results capture the outcome of your most recent dbt execution. What it contains:- Test pass/fail/warn status for each test
- Execution timestamps
- Error messages and stack traces
- Model build success/failure status
- Updates test case results showing pass/fail status
- Tracks when tests last ran
- Shows failure details for debugging
dbt run, dbt test, dbt build
Generating Your dbt Artifacts
Run these commands after your dbt models execute:dbt Core Artifact Storage
Artifact Accessibility
Since dbt Core runs within your infrastructure (for example, using Airflow or similar schedulers), Collate does not have direct access to the local file system where dbt executes. To enable ingestion, the dbt artifacts must be made accessible to Collate by storing them in a supported cloud storage service. Collate currently supports the following storage systems:- Amazon S3
- Google Cloud Storage (GCS)
- Azure Data Lake / Azure Blob Storage
- HTTP/HTTPS servers
- Local or shared filesystem
Configuration Steps
To configure dbt Core artifact ingestion:- Generate artifacts: Ensure dbt generates required files (manifest.json, catalog.json, run_results.json)
- Choose storage method: Select from S3, GCS, Azure, HTTP, or Local (see options below)
- Upload artifacts: Configure your workflow to upload artifacts to chosen storage
- Configure Collate: Provide storage path and credentials during ingestion setup
dbt Core Artifact Configuration
When using dbt Core, artifacts must be accessible to Collate. Choose your storage method:AWS S3
AWS deployments (ECS, EKS, EC2)
Google Cloud Storage
GCP deployments (GKE, Compute)
Azure Blob Storage
Azure deployments (AKS, VMs)
HTTP Server
Cloud-agnostic, static file servers
Local/Shared Filesystem
Single-server or Docker deployments
dbt Cloud Requirements
When using dbt Cloud, Collate integrates directly with dbt Cloud using APIs to retrieve metadata and execution details. See the dbt Cloud API Configuration Guide for complete setup instructions.Prerequisites
To configure dbt Cloud ingestion, you must have:- An active dbt Cloud account
- At least one dbt Cloud job configured to generate dbt artifacts
- A valid dbt Cloud API token with sufficient permissions
Supported Metadata
Using dbt Cloud integration, Collate can ingest:- dbt models and sources
- Column-level metadata
- Model and source lineage
- dbt test results (when tests are executed as part of the job)
- No external cloud storage configuration is required for dbt Cloud ingestion.
- Ensure that your dbt Cloud job is configured to generate documentation artifacts.
Collate integrates the below metadata from dbt
1. dbt Queries
Queries used to create the dbt models can be viewed in the dbt tab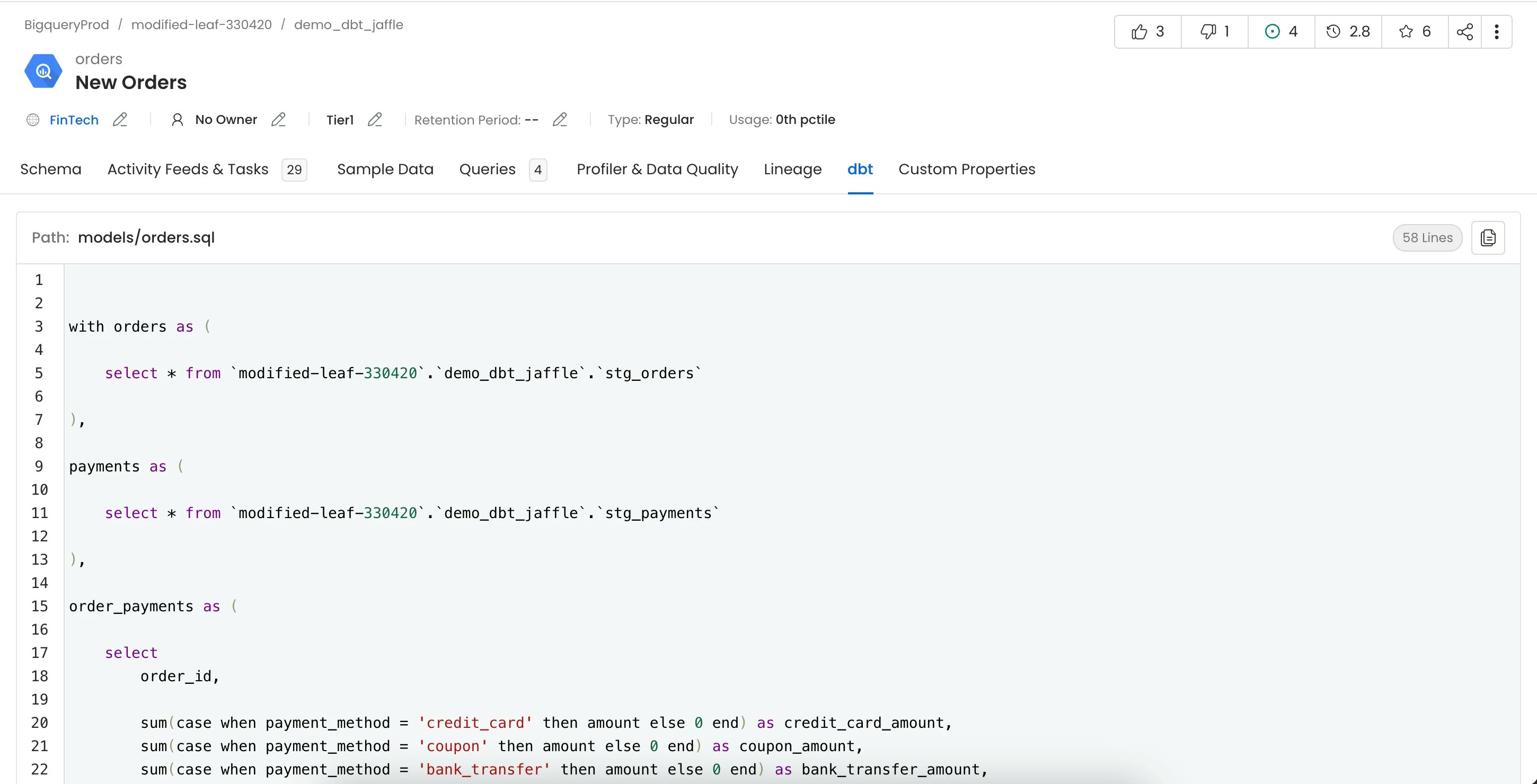
2. dbt Lineage
Lineage from dbt models can be viewed in the Lineage tab. For more information on how lineage is extracted from dbt take a look here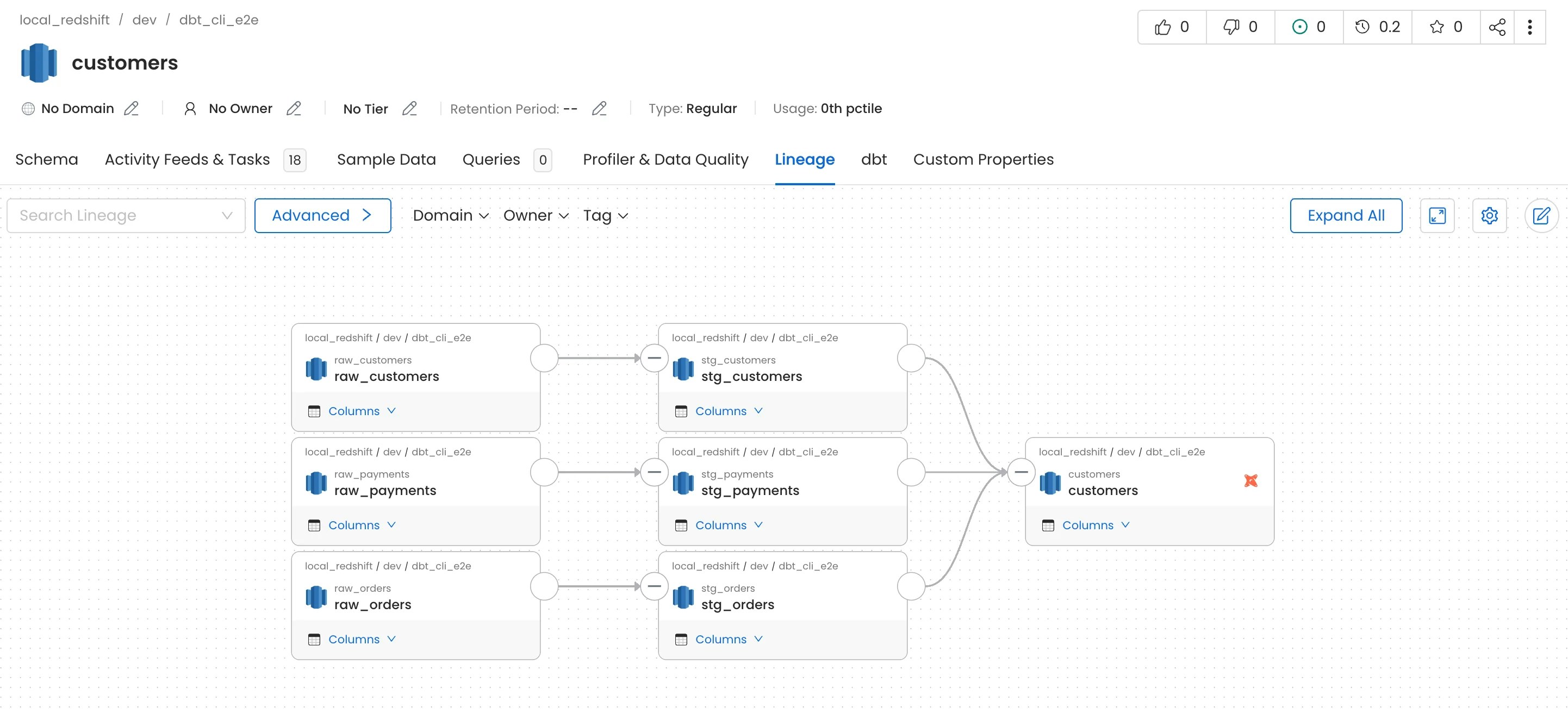
To capture lineage, the
compiled_code field must be present in the manifest.json file.- If
compiled_codeis missing, lineage will not be captured for that node. - To ensure
compiled_codeis populated in your dbt manifest, run the following commands in your dbt project:dbt compiledbt docs generate
3. dbt Tags
Table and column level tags can be imported from dbt Please refer here for adding dbt tags
4. dbt Owner
Owner from dbt models can be imported and assigned to respective tables Please refer here for adding dbt owner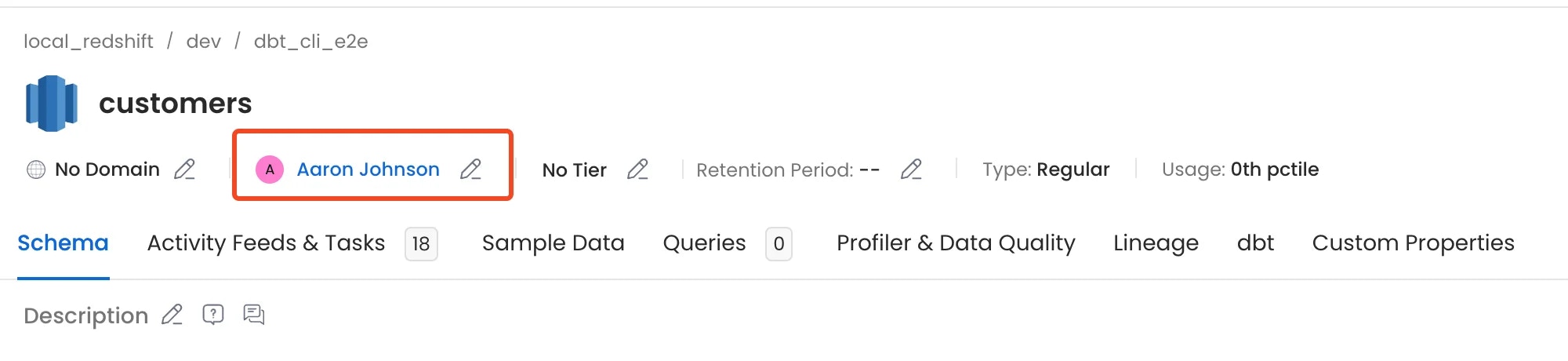
5. dbt Descriptions
Descriptions from dbtmanifest.json and catalog.json can be imported and assigned to respective tables and columns.
For more information and to control how the table and column descriptions are updated from dbt please take a look here
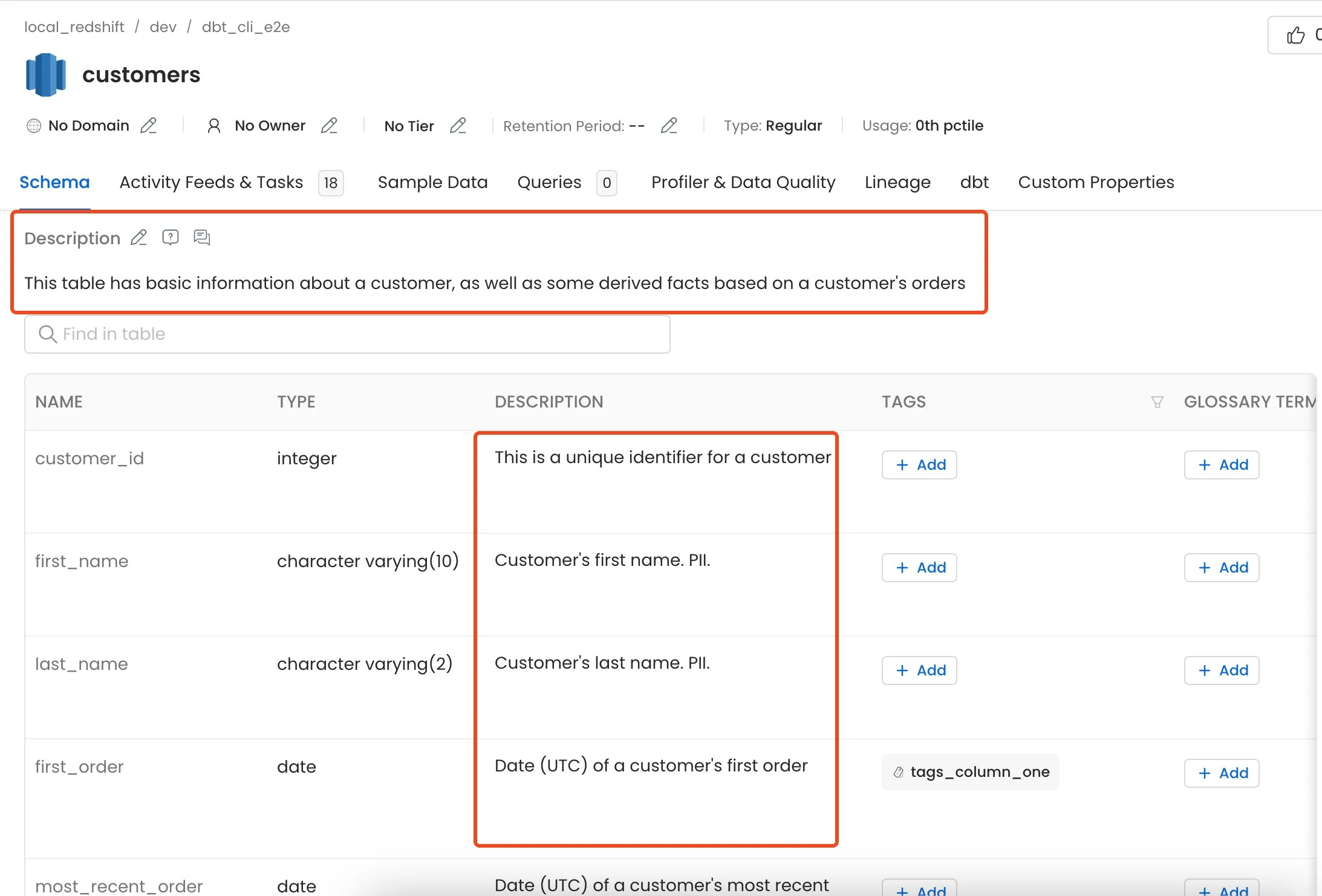
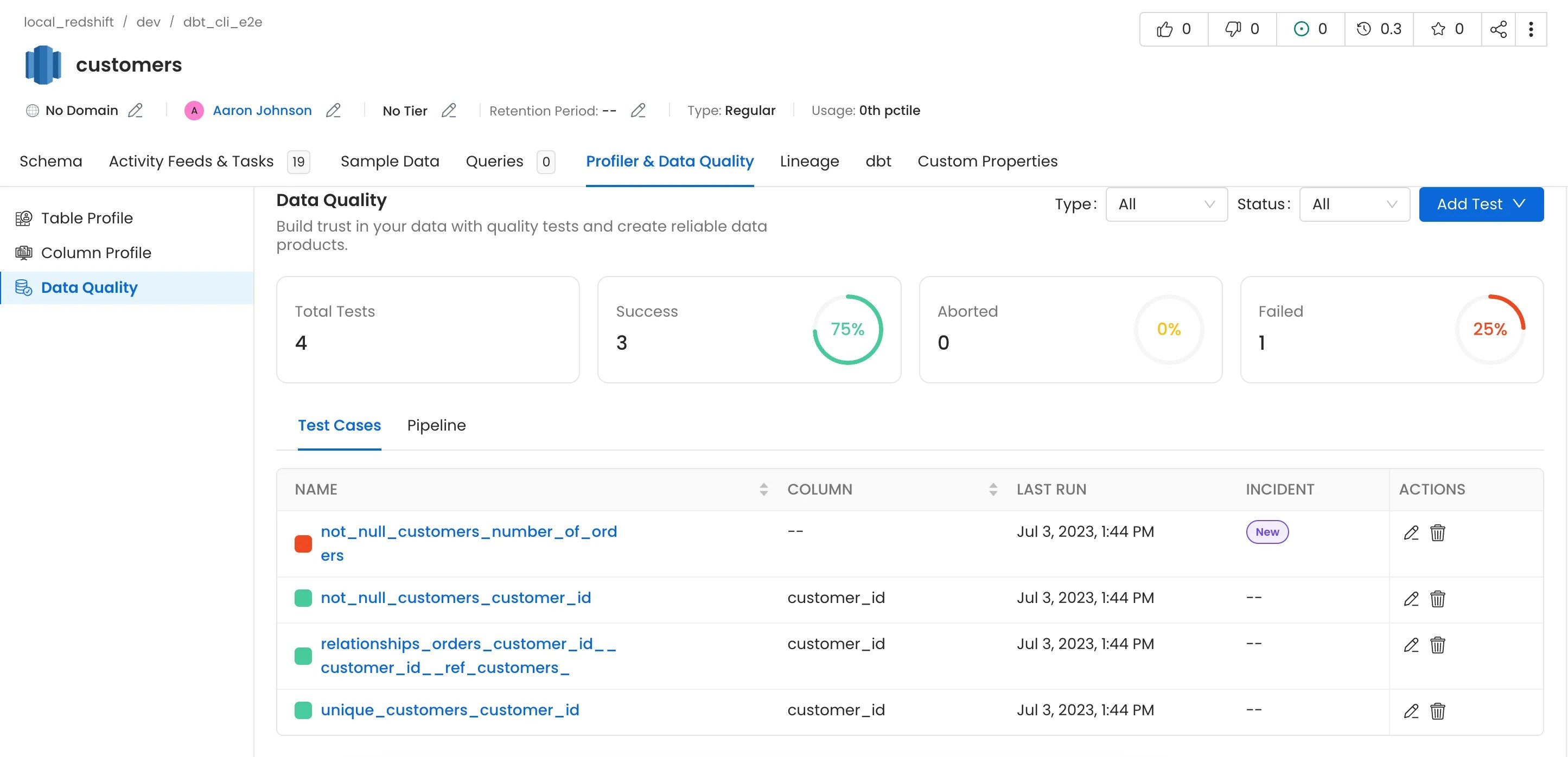
6. dbt Tests and Test Results
Tests from dbt will only be imported if therun_results.json file is passed.
7. dbt Tiers
Table and column level Tiers can be imported from dbt Please refer here for adding dbt tiers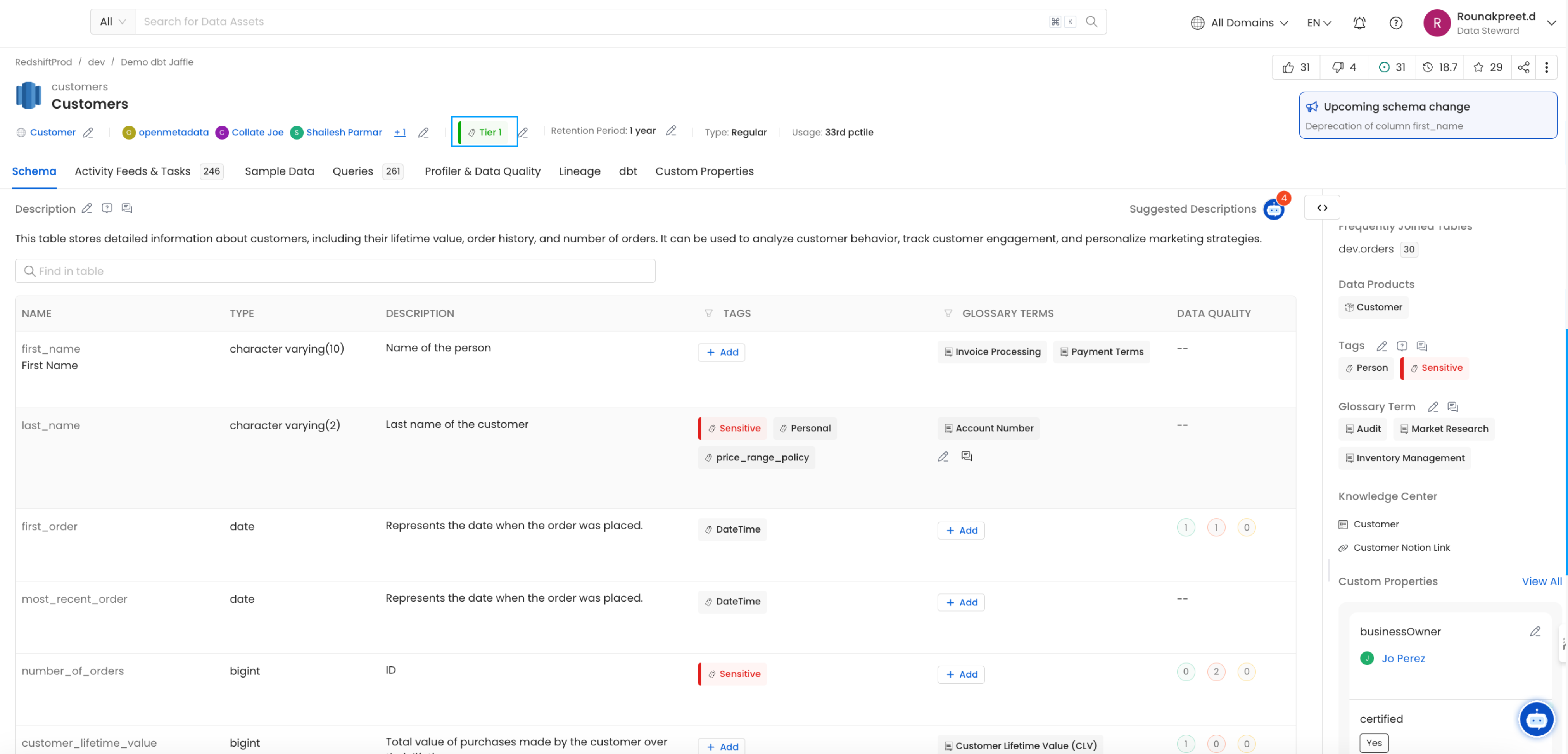
8. dbt Glossary
Table and column level Glossary can be imported from dbt Please refer here for adding dbt glossary