Requirements
dbt Cloud Versions
OpenMetadata is integrated with dbt Cloud up to version 1.8 and will continue to work for future dbt Cloud versions. The Ingestion framework uses dbt Cloud APIs to connect to dbt Cloud and fetch metadata.dbt Cloud Permissions
The dbt Cloud API User token or Service account token must have the permission to fetch metadata. To know more about permissions required refer here.dbt Cloud Account
- dbt Cloud multi-tenant or single tenant account is required.
- You must be on a Team or Enterprise plan.
- Your projects must be on dbt version 1.0 or later. Refer to Upgrade dbt version in Cloud to upgrade.
Metadata Ingestion
Connection Details
1
Connection Details
- Host: dbt Cloud Access URL eg.
https://abc12.us1.dbt.com. Go to your dbt Cloud account settings to know your Access URL. - Discovery API URL : dbt Cloud Access URL eg.
https://metadata.cloud.getdbt.com/graphql. Go to your dbt Cloud account settings to know your Discovery API url. Make sure you have/graphqlat the end of your URL. - Account Id : The Account ID of your dbt Cloud Project. Go to your dbt Cloud account settings to know your Account Id. This will be a numeric value but in openmetadata we parse it as a string.
- Job Ids : Optional. Job IDs of your dbt Cloud Jobs in your Project to fetch metadata for. Look for the segment after “jobs” in the URL. For instance, in a URL like
https://cloud.getdbt.com/accounts/123/projects/87477/jobs/73659994, the job ID is73659994. This will be a numeric value but in openmetadata we parse it as a string. If not passed all Jobs under the Account id will be ingested. - Project Ids : Optional. Project IDs of your dbt Cloud Account to fetch metadata for. Look for the segment after “projects” in the URL. For instance, in a URL like
https://cloud.getdbt.com/accounts/123/projects/87477/jobs/73659994, the job ID is87477. This will be a numeric value but in openmetadata we parse it as a string. If not passed all Projects under the Account id will be ingested. Note that if bothJob IdsandProject Idsare passed then it will filter out the jobs from the passed projects. anyJob Idsnot belonging to theProject Idswill also be filtered out. - Token : The Authentication Token of your dbt Cloud API Account. To get your access token you can follow the docs here. Make sure you have the necessary permissions on the token to run graphql queries and get job and run details.
2
Test the Connection
Once the credentials have been added, click on Test Connection and Save the changes.
3
Configure Metadata Ingestion
In this step we will configure the metadata ingestion pipeline,
Please follow the instructions below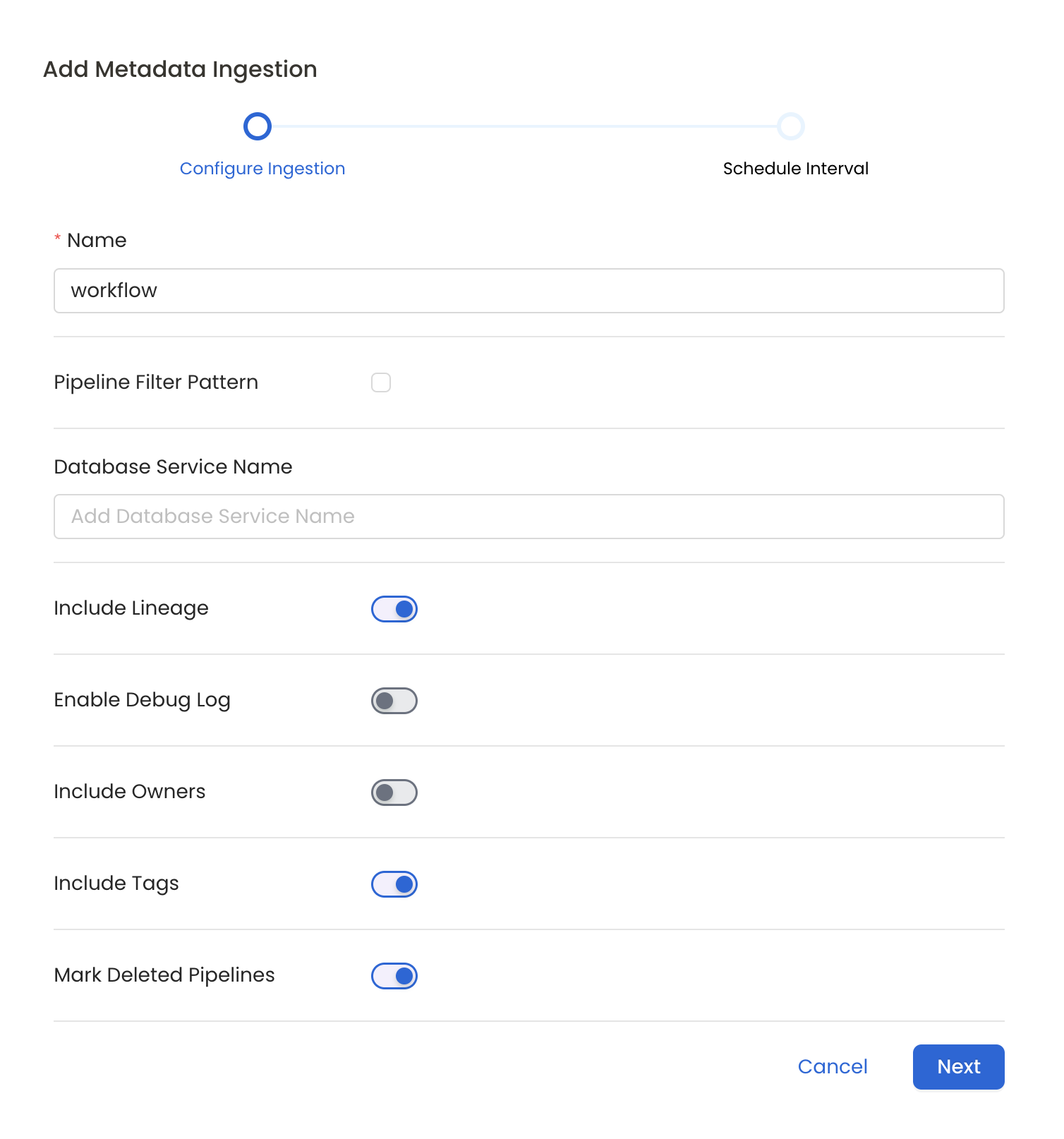
Metadata Ingestion Options
- Name: This field refers to the name of ingestion pipeline, you can customize the name or use the generated name.
- Pipeline Filter Pattern (Optional): Use to pipeline filter patterns to control whether or not to include pipeline as part of metadata ingestion.
- Include: Explicitly include pipeline by adding a list of comma-separated regular expressions to the Include field. OpenMetadata will include all pipeline with names matching one or more of the supplied regular expressions. All other schemas will be excluded.
- Exclude: Explicitly exclude pipeline by adding a list of comma-separated regular expressions to the Exclude field. OpenMetadata will exclude all pipeline with names matching one or more of the supplied regular expressions. All other schemas will be included.
- Include lineage (toggle): Set the Include lineage toggle to control whether to include lineage between pipelines and data sources as part of metadata ingestion.
- Enable Debug Log (toggle): Set the Enable Debug Log toggle to set the default log level to debug.
- Mark Deleted Pipelines (toggle): Set the Mark Deleted Pipelines toggle to flag pipelines as soft-deleted if they are not present anymore in the source system.
4
Schedule the Ingestion and Deploy
Scheduling can be set up at an hourly, daily, weekly, or manual cadence. The
timezone is in UTC. Select a Start Date to schedule for ingestion. It is
optional to add an End Date.Review your configuration settings. If they match what you intended,
click Deploy to create the service and schedule metadata ingestion.If something doesn’t look right, click the Back button to return to the
appropriate step and change the settings as needed.After configuring the workflow, you can click on Deploy to create the
pipeline.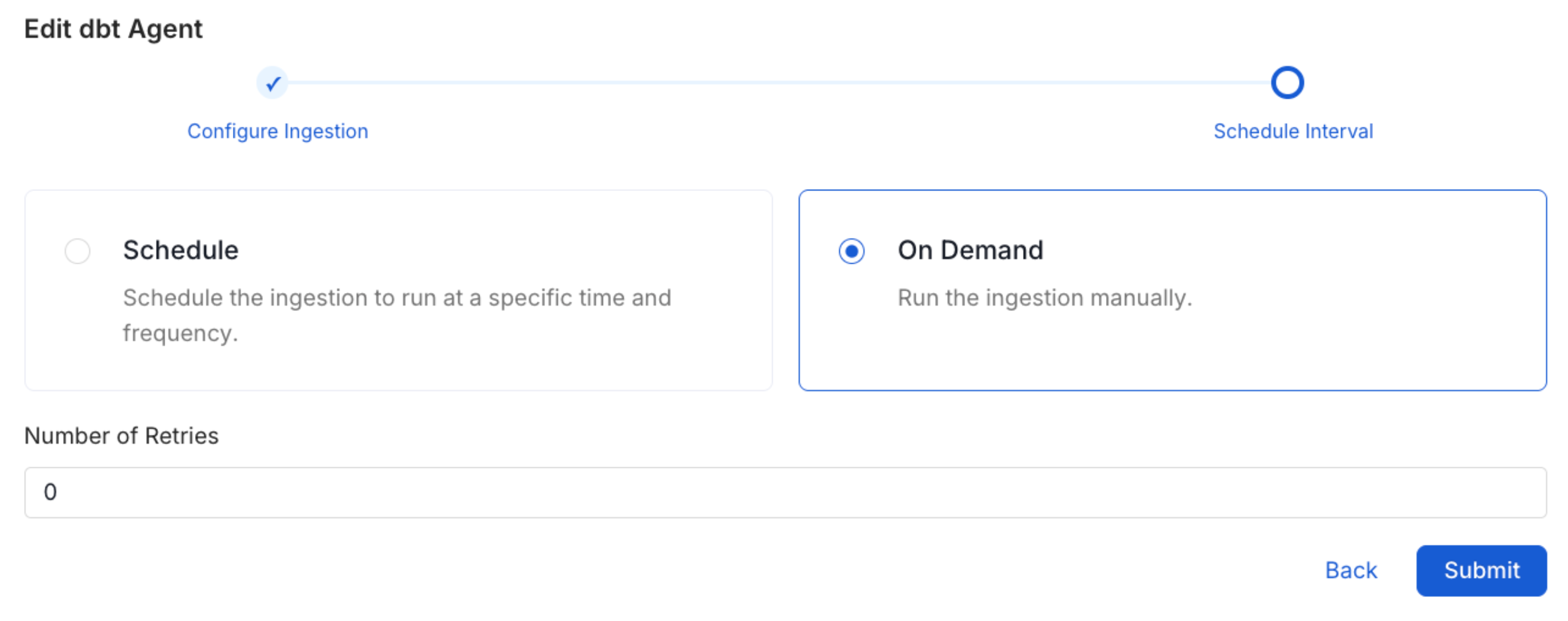
5
View the Ingestion Pipeline
Once the workflow has been successfully deployed, you can view the
Ingestion Pipeline running from the Service Page.
Displaying Lineage Information
Steps to retrieve and display the lineage information for a dbt Cloud service. Note that only the metadata from the last run will be used for lineage.- Ingest Source and Sink Database Metadata: Identify both the source and sink database used by the dbt Cloud service for example Redshift. Ingest metadata for these database.
- Ingest dbt Cloud Service Metadata: Finally, Ingest your dbt Cloud service. By successfully completing these steps, the lineage information for the service will be displayed.
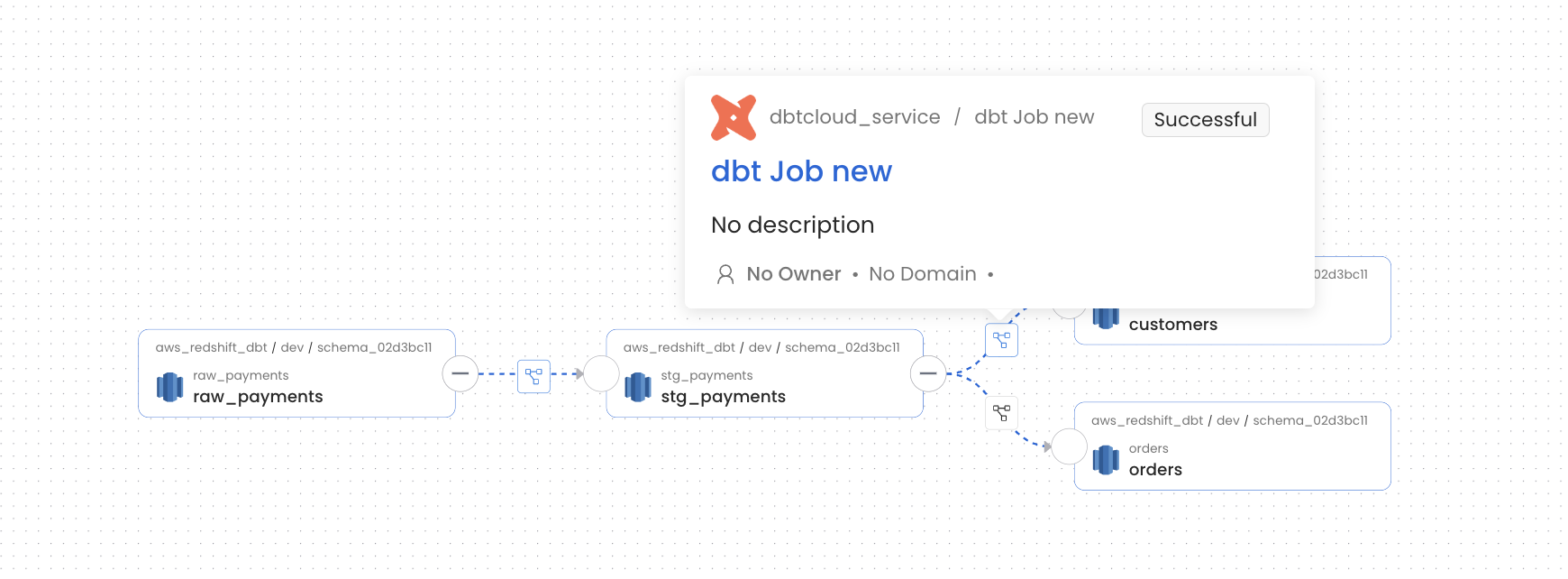
Missing Lineage
If lineage information is not displayed for a dbt Cloud service, follow these steps to diagnose the issue.- dbt Cloud Account: Make sure that the dbt Cloud instance you are ingesting have the necessary permissions to fetch jobs and run graphql queries over the API.
- Metadata Ingestion: Ensure that metadata for both the source and sink database is ingested and passed to the lineage system. This typically involves configuring the relevant connectors to capture and transmit this information.
- Last Run Successful: Ensure that the Last Run for a Job is successful as OpenMetadata gets the metadata required to build the lineage using the last Run under a Job.
Troubleshooting
dbt Cloud Troubleshooting
Learn more about how to troubleshoot common dbt Cloud connector issues and resolve configuration or ingestion errors.