Requirements
To access the ThoughtSpot APIs and import liveboards, charts, and data models from ThoughtSpot into OpenMetadata, you need appropriate permissions on your ThoughtSpot instance.ThoughtSpot Account Setup and Permissions
- Authentication Setup
ThoughtSpot supports multiple authentication methods:
- Basic Authentication: Username and password authentication. The user should have appropriate permissions to read metadata from ThoughtSpot.
- API Token Authentication: Use ThoughtSpot API tokens for authentication. Generate API tokens from your ThoughtSpot instance.
- API Permissions
Ensure your ThoughtSpot user or service account has the following permissions:
- Read access to liveboards and answers
- Read access to worksheets and data models
- Access to metadata APIs
- Export permissions for TML (ThoughtSpot Modeling Language) data
- Multi-tenant Configuration (Optional)
If you’re using ThoughtSpot Cloud with multiple organizations:
- Set the
Organization IDparameter to specify which organization to connect to (only for ThoughtSpot Cloud).
- Set the
Connection Details
- Host and Port:
The URL of your ThoughtSpot instance.
Examples:
- Cloud:
https://my-company.thoughtspot.cloud - On-premise:
https://thoughtspot.company.com - Local:
https://localhostIf running ingestion in Docker and ThoughtSpot is onlocalhost, usehost.docker.internal.
- Cloud:
- Authentication:
Choose one of the following:
- Basic Authentication:
- Username: Your ThoughtSpot username
- Password: Your ThoughtSpot password
- API Token Authentication:
- API Token: Your ThoughtSpot API token
- Basic Authentication:
- API Version:
The ThoughtSpot API version to use for metadata extraction.
v1: Legacy API version (callosum endpoints)v2: Current API version (recommended, default)
- Organization ID:
For multi-tenant ThoughtSpot Cloud deployments.
- Leave empty for single-tenant
- Set to your org ID for multi-tenant
Metadata Ingestion
Connection Configuration
1
Test the Connection
Once the credentials have been added, click on Test Connection and Save the changes.
2
Configure Metadata Ingestion
After adding and testing the dashboard service, configure the metadata ingestion pipeline. To configure, follow the steps below: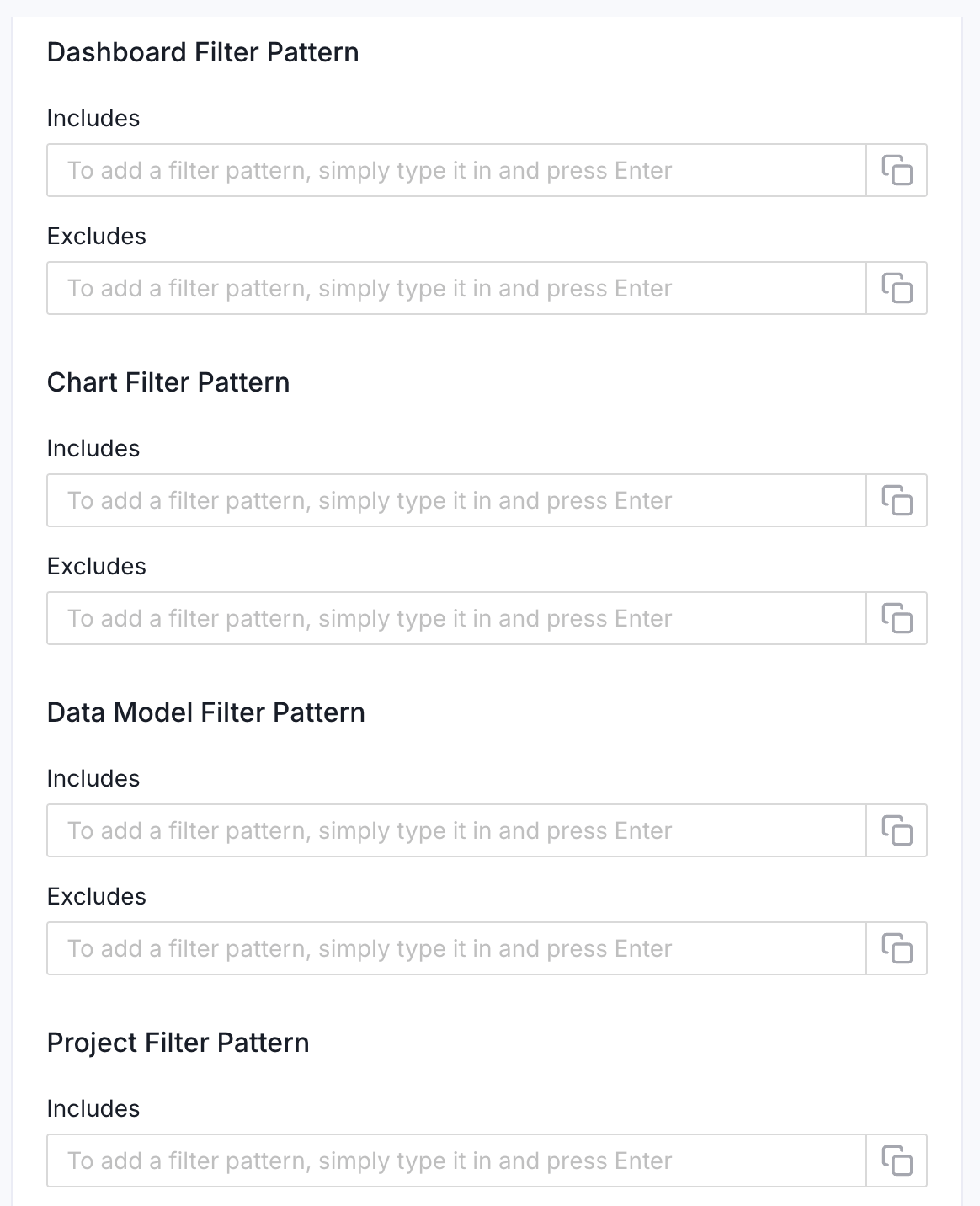
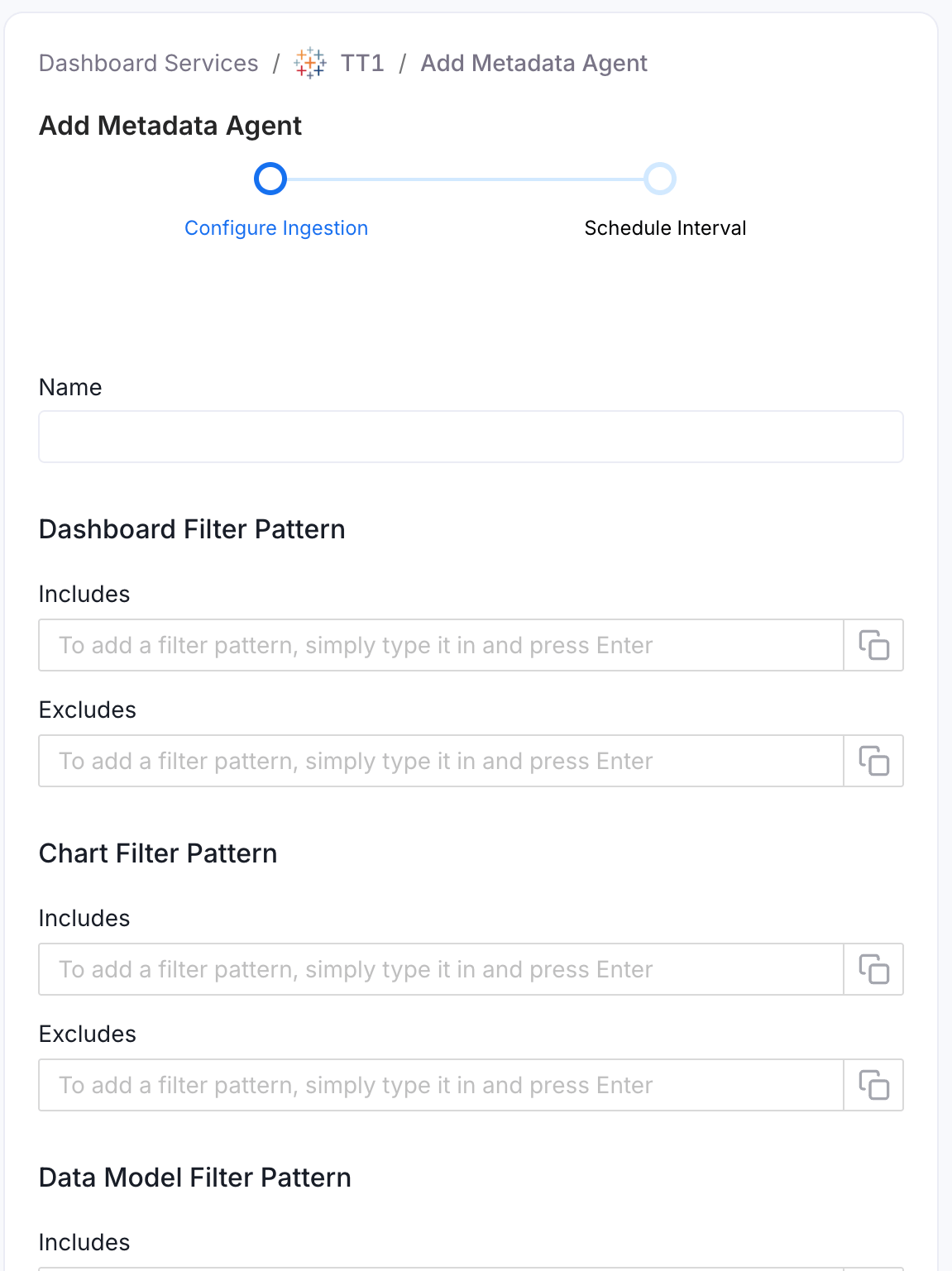
- Navigate to Settings > Services > Dashboards.
- On the Dashboards services page, click the service you’ve added.
- Go to the Agents tab, and then click Add Agent > Add Metadata Agent.
- Configure the ingestion details. See Metadata Ingestion Options.
Metadata Ingestion Options
- Name: This field is the name of the ingestion pipeline. Customize it or use the generated name.
- Dashboard Filter Pattern (Optional): Use it to control whether to include dashboards as part of metadata ingestion.
- Include: Explicitly include dashboards by adding comma-separated regular expressions to the ‘Include’ field. OpenMetadata will include all dashboards with names matching one or more of the supplied regular expressions. All other dashboards will be excluded.
- Exclude: Explicitly exclude dashboards by adding comma-separated regular expressions to the ‘Exclude’ field. OpenMetadata will exclude all dashboards with names matching one or more of the supplied regular expressions. All other dashboards will be included.
- Chart Filter Pattern (Optional): Use it to control whether to include charts as part of metadata ingestion.
- Include: Explicitly include charts by adding comma-separated regular expressions to the ‘Include’ field. OpenMetadata will include all charts with names matching one or more of the supplied regular expressions. All other charts will be excluded.
- Exclude: Explicitly exclude charts by adding comma-separated regular expressions to the ‘Exclude’ field. OpenMetadata will exclude all charts with names matching one or more of the supplied regular expressions. All other charts will be included.
- Data Model Filter Pattern (Optional): Use it to control whether to include data models as part of metadata ingestion.
- Include: Explicitly include data models by adding comma-separated regular expressions to the ‘Include’ field. OpenMetadata will include all data models with names matching one or more of the supplied regular expressions. All other data models will be excluded.
- Exclude: Explicitly exclude data models by adding comma-separated regular expressions to the ‘Exclude’ field. OpenMetadata will exclude all data models with names matching one or more of the supplied regular expressions. All other data models will be included.
- Project Filter Pattern: Filter the dashboards, charts, and data sources by projects. Note that all of them support regex as include or exclude. For example, “My project, My proj.*, .*Project”.
- Enable Debug Log: Enable this toggle to use debug-level logging.
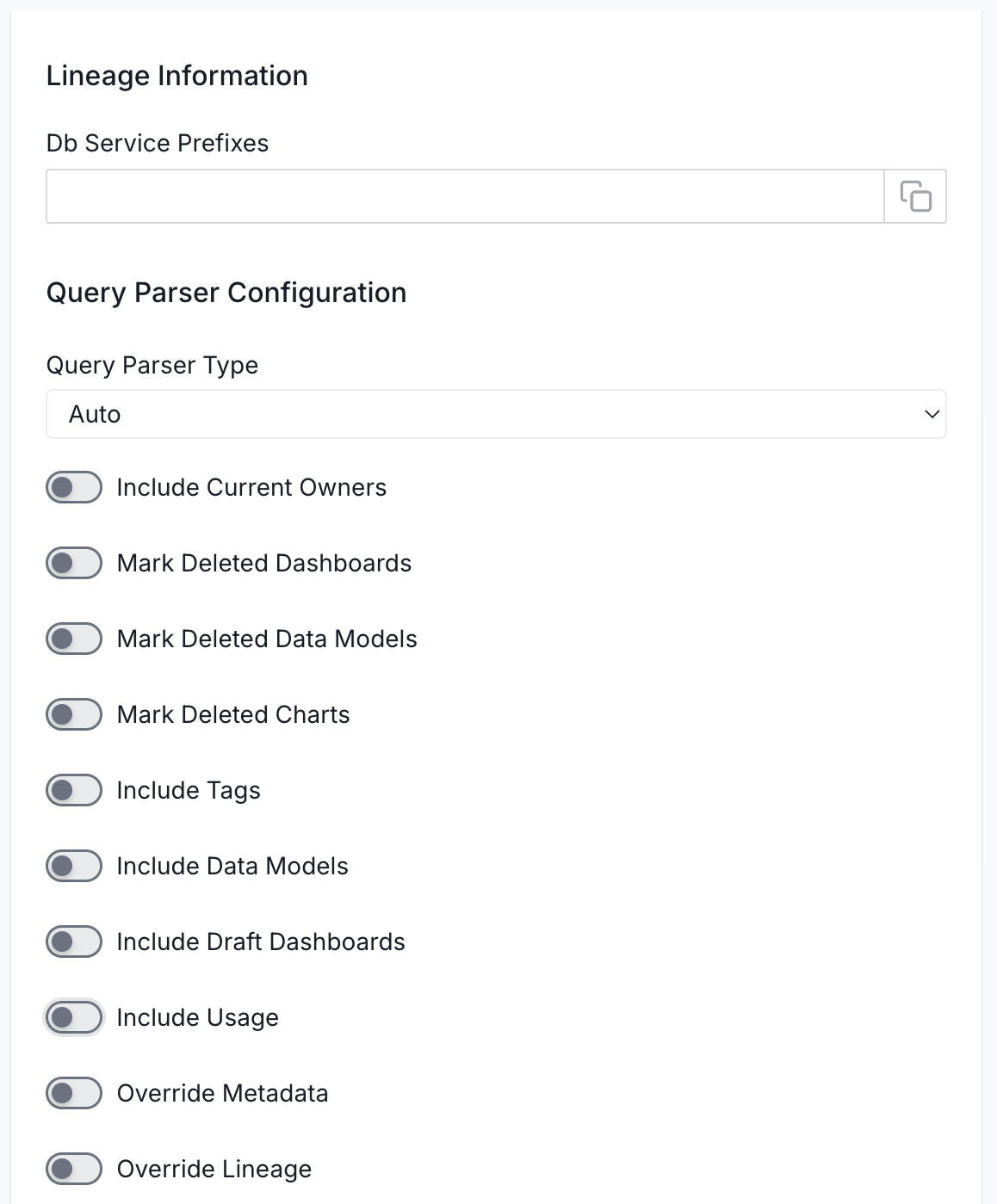
- Lineage Information (Optional): Configure this section to enable lineage between your dashboards and the database tables they are built on. OpenMetadata uses the database service name to match and draw the lineage path from table to dashboard.
- Db Service Prefixes: Enter one or more service path prefixes to tell OpenMetadata where to look for the source tables used by your dashboards. Supported formats:
DBServiceName—matches all tables in the serviceDBServiceName.DatabaseName—matches tables in a specific databaseDBServiceName.DatabaseName.SchemaName—matches tables in a specific schemaDBServiceName.DatabaseName.SchemaName.TableName—matches a specific table
- Db Service Prefixes: Enter one or more service path prefixes to tell OpenMetadata where to look for the source tables used by your dashboards. Supported formats:
- Query Parser Configuration: Controls how OpenMetadata parses SQL queries to extract lineage. Use this to select the SQL parser that best fits your data source’s dialect.
- Query Parser Type: Choose the SQL parser for lineage extraction:
- Auto (default): Automatically tries SqlGlot first, falls back to SqlFluff, then SqlParse. Recommended for best results.
- SqlGlot: High-performance parser with good dialect support. Falls back to SqlParse on failure.
- SqlFluff: Comprehensive but slower parser with strong dialect support. Falls back to SqlParse on failure.
- Query Parser Type: Choose the SQL parser for lineage extraction:
- Include Current Owners: Enable this toggle to control whether to include owners for the ingested entity if the owner email matches a user stored in the Collate server as part of metadata ingestion. If the ingested entity already exists and has an owner, the owner will not be overwritten.
- Mark Deleted Dashboards: Optional configuration to soft delete dashboards in OpenMetadata if the source dashboards are deleted. After deleting, all associated entities like lineage and other related data for that dashboard will be deleted.
- Mark Deleted Data Models: Optional configuration to soft delete data models in OpenMetadata if the source data models are deleted. After deleting, all associated entities with that data model will be deleted.
- Mark Deleted Charts: Optional configuration to soft delete charts in OpenMetadata if the source charts are deleted. After deleting, all associated entities with that chart will be deleted.
- Include Tags: Enable this toggle to control whether to include tags in metadata ingestion.
- Include Data Models: Enable this toggle to control whether to include data models as part of metadata ingestion.
- Include Draft Dashboard: Enable this toggle to include draft dashboards. By default, this is enabled.
- Include Usage: Enable this toggle to control whether to include usage data as part of metadata ingestion.
- Override Metadata: Enable this toggle to control whether to override the existing metadata in the Collate server with the metadata fetched from the source. If enabled, the metadata fetched from the source will override the existing metadata in OpenMetadata. If disabled, only fields that have no value in OpenMetadata will be updated. This is applicable for fields like description, tags, owner, and displayName.
- Override Lineage: Enable this toggle to control whether to override the existing lineage in OpenMetadata with the lineage fetched from the source. If enabled, existing lineage will be replaced. If disabled, new lineage edges will be added without removing existing ones.
3
Schedule the Ingestion and Deploy
Scheduling can be set up at an hourly, daily, weekly, or manual cadence. The
timezone is in UTC. Select a Start Date to schedule for ingestion. It is
optional to add an End Date.Review your configuration settings. If they match what you intended,
click Deploy to create the service and schedule metadata ingestion.If something doesn’t look right, click the Back button to return to the
appropriate step and change the settings as needed.After configuring the workflow, you can click on Deploy to create the
pipeline.
4
View the Ingestion Pipeline
Once the workflow has been successfully deployed, you can view the
Ingestion Pipeline running from the Service Page.
- Database service names to be configured in the lineage information
- Access to TML export functionality Enable debug logging to troubleshoot issues:
Troubleshooting
ThoughtSpot Troubleshooting
Learn more about how to troubleshoot common ThoughtSpot connector issues and resolve configuration or ingestion errors.