> ## Documentation Index
> Fetch the complete documentation index at: https://docs.getcollate.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Custom Recognizers for Auto-Classification
> Configure custom detection rules to automatically identify and tag sensitive data using pattern matching, exact terms, and pre-built recognizers.
# Custom recognizers
Custom recognizers let you configure detection rules that automatically identify and tag sensitive data during profiling and ingestion. Unlike the default auto-classification, recognizers give you full control over what patterns to detect and how to tag them.
## What are recognizers?
Recognizers are configurable detection rules attached to classification tags. When profiling runs, recognizers analyze your data and automatically apply tags when they detect matching patterns. Each auto-applied tag includes metadata showing which recognizer detected it and the confidence score.
**Key benefits:**
* **Customizable detection**: Define your own patterns for organization-specific data (employee IDs, internal codes, custom formats)
* **Multiple detection methods**: Use regex patterns, exact terms, or 45+ pre-built detectors
* **Learning from feedback**: Users can report false positives, which automatically refine recognizer behavior
* **Confidence-based tagging**: Set minimum confidence thresholds to control precision
## Recognizer types
### Pattern recognizers
Use regular expressions to match structured data formats.
**Best for:**
* Emails, phone numbers, IP addresses
* Custom organizational patterns (employee IDs: `EMP-\d{5}`)
* Any data following predictable patterns
**Example:**
```
Pattern: \b\d{3}[-.]?\d{3}[-.]?\d{4}\b
Detects: US phone numbers (123-456-7890, 123.456.7890)
```
### Exact Terms recognizers
Match specific values from a predefined list.
**Best for:**
* Known sensitive values (internal project codes, department names)
* Fixed vocabularies (country codes, status values)
* Cases requiring exact matches (no pattern variation)
**Example:**
```
Terms: ["PROJECT_ALPHA", "PROJECT_BETA", "PROJECT_GAMMA"]
Detects: Exact matches of confidential project codes
```
### Predefined recognizers
Built-in detectors from Microsoft Presidio (45+ recognizers).
**Best for:**
* Standard PII (credit cards, SSNs, passports)
* International identifiers (IBANs, UK NHS numbers, ES NIF)
* When you don't want to write custom regex
**Categories:**
* **Financial**: CreditCardRecognizer, IbanRecognizer, UsBankRecognizer
* **Personal ID**: UsSsnRecognizer, UsPassportRecognizer, InPanRecognizer, InAadhaarRecognizer
* **Healthcare**: NhsRecognizer, MedicalLicenseRecognizer
* **Contact**: EmailRecognizer, PhoneRecognizer, UrlRecognizer
## Creating a Recognizer
1. Navigate to **Govern** > **Classification**.
2. Select a classification (e.g., "PII").
3. Click on a tag within that classification.
4. Go to the **Recognizers** tab.
5. Click **Add Recognizer**.
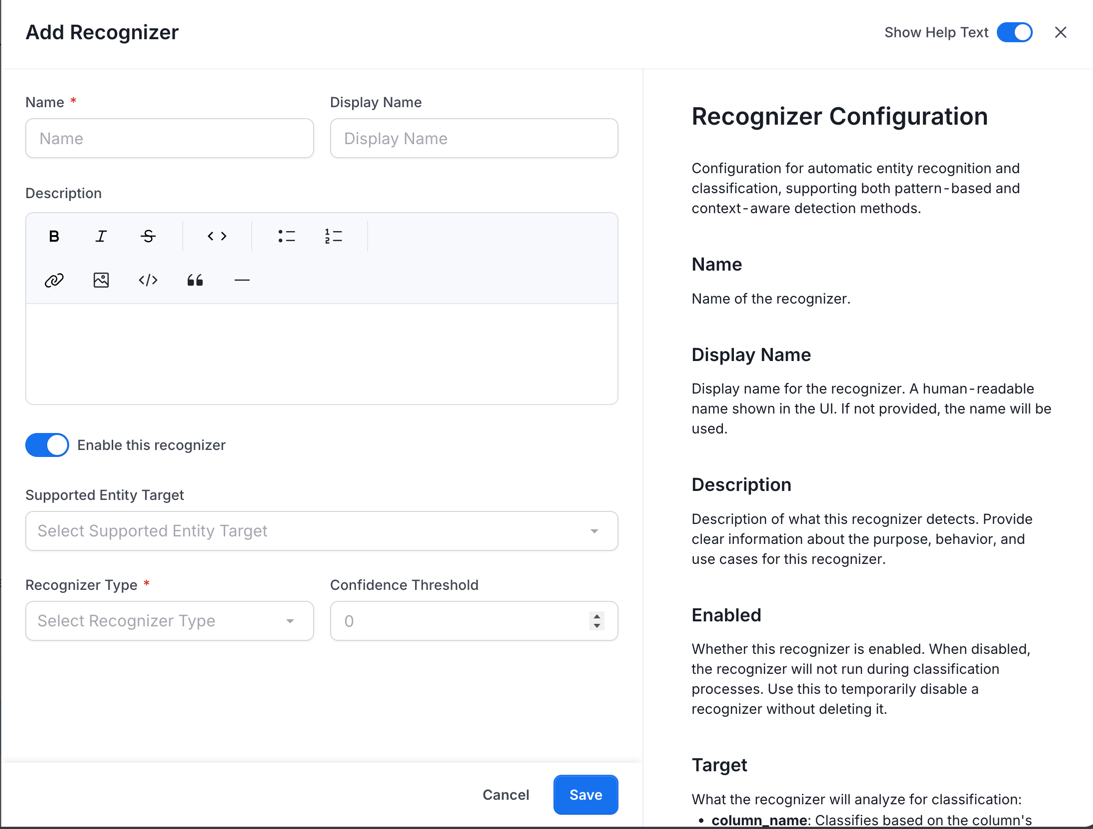
 6. Configure the recognizer:
* **Name**: Unique identifier (e.g., `email_pattern`)
* **Display Name**: A unique descriptive name (e.g., "Email Pattern Detector")
* **Description**: What this recognizer detects
* **Supported Entity Target**: Choose where to analyze:
* **Content**: Analyze actual data values in sampled rows. Tags are applied when the confidence score meets the threshold.
* **Column Name**: Apply the tag based on the column name alone — no sample data is needed. Use this when sampled values are masked, anonymized, or unavailable.
* **Recognizer Type**: Select the detection method:
* **Pattern**: Match using regular expressions.
To set up Pattern recognizer, see [Pattern Recognizer Settings](#pattern-recognizer-settings).
* **Exact Term**: Match specific values from a list.
To set up Exact Term recognizer, see [Exact Terms Settings](#exact-terms-settings).
* **Pre-Defined**: Use a built-in Presidio recognizer.
To set up Pre-Defined recognizer, see [Predefined Recognizer Settings](#predefined-recognizer-settings).
* **Confidence Threshold**: Minimum score (0.0-1.0) to apply tag (default: 0.6)
6. Configure the recognizer:
* **Name**: Unique identifier (e.g., `email_pattern`)
* **Display Name**: A unique descriptive name (e.g., "Email Pattern Detector")
* **Description**: What this recognizer detects
* **Supported Entity Target**: Choose where to analyze:
* **Content**: Analyze actual data values in sampled rows. Tags are applied when the confidence score meets the threshold.
* **Column Name**: Apply the tag based on the column name alone — no sample data is needed. Use this when sampled values are masked, anonymized, or unavailable.
* **Recognizer Type**: Select the detection method:
* **Pattern**: Match using regular expressions.
To set up Pattern recognizer, see [Pattern Recognizer Settings](#pattern-recognizer-settings).
* **Exact Term**: Match specific values from a list.
To set up Exact Term recognizer, see [Exact Terms Settings](#exact-terms-settings).
* **Pre-Defined**: Use a built-in Presidio recognizer.
To set up Pre-Defined recognizer, see [Predefined Recognizer Settings](#predefined-recognizer-settings).
* **Confidence Threshold**: Minimum score (0.0-1.0) to apply tag (default: 0.6)
 Auto-classification samples rows directly from the source during each run — it does not rely on previously stored sample data. The **Store Sample Data** setting controls whether those rows are saved in OpenMetadata, not whether classification can run. Tags won't be applied if the connector cannot reach the source, sampled values are masked or anonymized, or the confidence score falls below the threshold. If classification is unreliable for a column, use [Governance Automations](/how-to-guides/data-governance/automation) to tag by name pattern instead.
7. Click **Save**
### Pattern Recognizer Settings
The following fields appear when **Recognizer Type** is set to **Pattern**:
* **Add Pattern**: Add one or more regex patterns, each with:
* **Name**: A unique descriptive name, helps identify the purpose of each pattern when you have multiple patterns in one recognizer. For example, Visa Format, MasterCard Format, AmEx Format.
* **Regex**: Regular expression pattern to match against the content or column name. Use standard regex syntax.
* **Score**: Confidence score assigned when this pattern matches. Values range from 0.0 to 1.0. Use higher scores for more specific/reliable patterns and lower scores for broader patterns.
* **Supported Language**: Language scope for this recognizer. Defaults to **All**.
* **Context** (optional): List of context words that can help boost confidence score. These words provide additional context for pattern matching and can increase confidence when found near the matched pattern. For example, for a credit card recognizer, context might include: "card", "credit", "payment", "cvv".
* **Regex Flags**: Toggle **Dot All**, **Multiline**, and **Ignore Case** as needed.
* **Dot All**: Enable dot-all regex flag. When enabled, the dot (.) metacharacter matches newline characters as well as any other character. Useful for multi-line pattern matching.
* **Multiline**: Enable multiline regex flag. When enabled, the ^ and \$ anchors match at line breaks in addition to the start and end of the entire string. Useful for patterns that should match line by line.
* **Ignore Case**: Enable case-insensitive matching. When enabled, the pattern matches regardless of letter case (e.g., "EMAIL" matches "email", "Email", "EMAIL").
**Example: Email Detection**
```
Name: email_pattern
Target: Content
Patterns:
Name: "Standard Email"
Regex: [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}
Score: 0.9
Context: ["email", "e-mail", "contact"]
Confidence Threshold: 0.7
```
### Exact Terms Settings
The following fields appear when **Recognizer Type** is set to **Exact Term**:
* **Term List**: List of specific values to match against. The recognizer will identify data that exactly matches any value in this list. Useful for identifying specific sensitive terms, names, or identifiers that should be flagged. For example, \["confidential", "secret", "internal-only", "do-not-share"]
* **Supported Language**: Language scope for this recognizer. Defaults to **All**.
* **Regex Flags**: Toggle **Dot All**, **Multiline**, and **Ignore Case** as needed.
* **Dot All**: Enable dot-all regex flag. When enabled, the dot (.) metacharacter matches newline characters as well as any other character. Useful for multi-line pattern matching.
* **Multiline**: Enable multiline regex flag. When enabled, the ^ and \$ anchors match at line breaks in addition to the start and end of the entire string. Useful for patterns that should match line by line.
* **Ignore Case**: Enable case-insensitive matching. When enabled, the pattern matches regardless of letter case (e.g., "EMAIL" matches "email", "Email", "EMAIL").
**Example: Internal Codes**
```
Name: internal_dept_codes
Target: Content
Exact Terms:
- DEPT_001_CONFIDENTIAL
- DEPT_002_RESTRICTED
Ignore Case: true
Confidence Threshold: 0.9
```
### Predefined Recognizer Settings
The following fields appear when **Recognizer Type** is set to **Pre-Defined**:
* **Pre-Defined Recognizer**: Select a pre-configured recognizer from the system.
* **Financial**: AbaRoutingRecognizer, CreditCardRecognizer, IbanRecognizer, UsBankRecognizer
* **Personal ID**: UsSsnRecognizer, UsItinRecognizer, UsPassportRecognizer, UsLicenseRecognizer, InPanRecognizer, InAadhaarRecognizer
* **Healthcare**: NhsRecognizer, MedicalLicenseRecognizer, AuMedicareRecognizer
* **Contact**: EmailRecognizer, PhoneRecognizer, UrlRecognizer, IpRecognizer
* **Geographic**: EsNifRecognizer, EsNieRecognizer, UkNinoRecognizer, AuAbnRecognizer, PlPeselRecognizer
* **Advanced**: SpacyRecognizer, StanzaRecognizer, TransformersRecognizer, GLiNERRecognizer
* **Context** (optional): Context that helps boost the confidence score when found near detected entities. For example, for EmailRecognizer, context might include: "email", "contact", "address", "send".
* **Supported Language**: Language scope for this recognizer. Defaults to **All**.
**Example: SSN Detection**
```
Name: us_ssn_detector
Target: Content
Predefined Recognizer: UsSsnRecognizer
Context: ["SSN", "social", "security"]
Confidence Threshold: 0.8
```
### Column Name Recognizer Settings
When **Target** is set to **Column Name**, the recognizer matches against the column name itself rather than sampled row values. This is useful when sampled data is masked, anonymized, or unavailable.
Use **Exact Terms** type for known column names:
**Example: Tag columns named `email`, `person_id`, or `customer_email`**
```
Name: pii_column_name_detector
Target: Column Name
Type: Exact Terms
Exact Terms:
- email
- person_id
- customer_email
Ignore Case: true
Confidence Threshold: 1.0
```
Use **Pattern** type for column name conventions that follow a predictable format:
**Example: Tag any column ending in `_email` or `_id`**
```
Name: pii_column_pattern_detector
Target: Column Name
Type: Pattern
Patterns:
- Name: "Email columns"
Regex: .*_email$
Score: 1.0
- Name: "ID columns"
Regex: .*_id$
Score: 0.8
Confidence Threshold: 0.8
```
## Managing recognizers
### View all recognizers
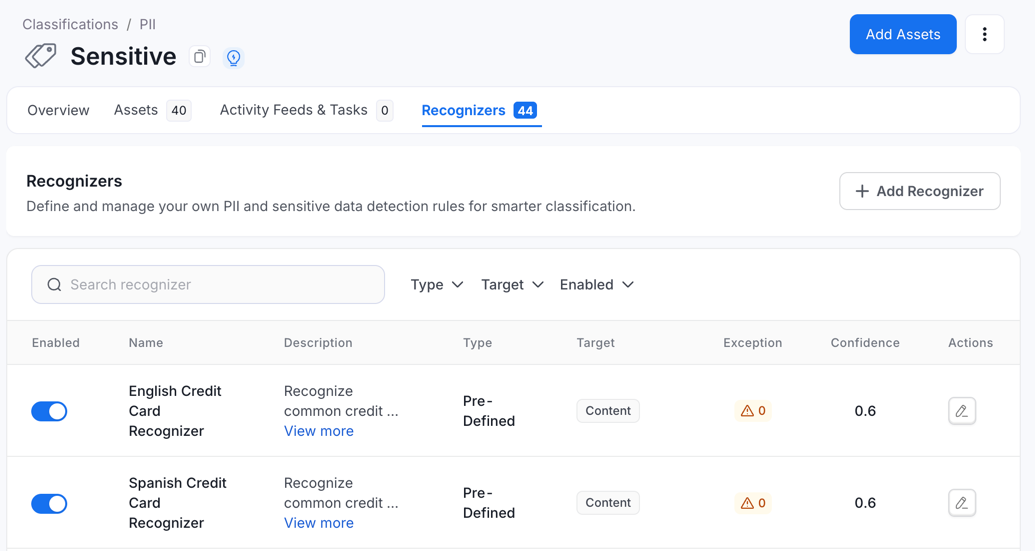
The recognizers tab displays all recognizers for a tag with columns:
* **Enabled**: Toggle to activate/deactivate
* **Name** & **Description**
* **Type**: Pattern, Exact Terms, Predefined, or Context
* **Target**: Content or Column Name
* **Exceptions**: Number of entities excluded from this recognizer
* **Confidence**: Confidence threshold
### Filter & Search
Use filters to narrow the list:
* **Type**: Pattern, Exact Terms, Predefined, Context
* **Target**: Content, Column Name
* **Enabled**: Enabled, Disabled
Use the search box to find recognizers by name or description.
### Edit a Recognizer
1. Click **Edit** (pencil icon) in the Actions column
2. Modify fields in the form
3. Click **Save**
**Note**: Changes only apply to future classification runs, not retroactively.
### Delete a Recognizer
1. Click **Delete** (trash icon) in the Actions column
2. Confirm deletion
**Warning**: Deleting a recognizer does not remove tags it previously applied. You must manually remove those tags if needed.
### Enable/Disable recognizers
Use the toggle switch in the Enabled column to temporarily stop a recognizer without deleting it. Changes take effect on the next classification run.
### Managing Exceptions
Click the **Exceptions** count to view entities where this recognizer should not run. Exceptions are automatically added when [feedback is approved](/how-to-guides/data-governance/classification/auto-classification/feedback).
You can manually delete exceptions:
1. Click exceptions count
2. View list in the exceptions panel
3. Click delete on specific exceptions
4. Confirm removal
## Best Practices
### Creating effective recognizers
1. **Start with high confidence**: Begin with threshold 0.7-0.8, adjust if needed
2. **Test patterns first**: Validate regex patterns with sample data before creating the recognizer
3. **Use context words**: Add relevant context to reduce false positives
4. **Multiple patterns**: Create separate patterns for different formats (e.g., phone: `(123)456-7890` vs `123-456-7890`)
5. **Descriptive names**: Use clear, searchable names and descriptions
### Managing False Positives
1. **Review feedback regularly**: Check pending feedback from users
2. **Adjust thresholds**: If too many false positives, increase confidence threshold
3. **Refine patterns**: Edit patterns to be more specific
4. **Add context words**: Boost confidence for true positives with relevant context
### Performance Tips
1. **Target appropriately**: Use "Column Name" target when possible (faster than content analysis)
2. **Disable unused recognizers**: Deactivate recognizers you no longer need
3. **Combine patterns**: Use one recognizer with multiple patterns instead of many single-pattern recognizers
4. **Limit context words**: Keep context word lists concise (under 20 words)
## Troubleshooting
### Recognizer Not Detecting Data
**Check:**
* Recognizer is Enabled
* Confidence threshold not too high
* Pattern syntax is correct (test with a regex tool)
* Target matches your use case (Content vs Column Name)
* Entity is not in the exception list
* Profiler and auto-classification are enabled in ingestion config
### Too Many False Positives
**Solutions:**
* Increase confidence threshold
* Add context words for true positives
* Make patterns more specific
* Consider using exact terms recognizer instead
* Let users submit feedback to build exception lists
### Pattern Not Matching
**Common issues:**
* Missing escape characters in regex (use `\\d` not `\d`)
* Incorrect regex flags (check case sensitivity, multi-line)
* Pattern too specific or too broad
* Test your pattern at [regex101.com](https://regex101.com) first
## Next Steps
Learn how to report false positives and improve recognizer accuracy through user feedback
Understand the default PII tagging logic
Auto-classification samples rows directly from the source during each run — it does not rely on previously stored sample data. The **Store Sample Data** setting controls whether those rows are saved in OpenMetadata, not whether classification can run. Tags won't be applied if the connector cannot reach the source, sampled values are masked or anonymized, or the confidence score falls below the threshold. If classification is unreliable for a column, use [Governance Automations](/how-to-guides/data-governance/automation) to tag by name pattern instead.
7. Click **Save**
### Pattern Recognizer Settings
The following fields appear when **Recognizer Type** is set to **Pattern**:
* **Add Pattern**: Add one or more regex patterns, each with:
* **Name**: A unique descriptive name, helps identify the purpose of each pattern when you have multiple patterns in one recognizer. For example, Visa Format, MasterCard Format, AmEx Format.
* **Regex**: Regular expression pattern to match against the content or column name. Use standard regex syntax.
* **Score**: Confidence score assigned when this pattern matches. Values range from 0.0 to 1.0. Use higher scores for more specific/reliable patterns and lower scores for broader patterns.
* **Supported Language**: Language scope for this recognizer. Defaults to **All**.
* **Context** (optional): List of context words that can help boost confidence score. These words provide additional context for pattern matching and can increase confidence when found near the matched pattern. For example, for a credit card recognizer, context might include: "card", "credit", "payment", "cvv".
* **Regex Flags**: Toggle **Dot All**, **Multiline**, and **Ignore Case** as needed.
* **Dot All**: Enable dot-all regex flag. When enabled, the dot (.) metacharacter matches newline characters as well as any other character. Useful for multi-line pattern matching.
* **Multiline**: Enable multiline regex flag. When enabled, the ^ and \$ anchors match at line breaks in addition to the start and end of the entire string. Useful for patterns that should match line by line.
* **Ignore Case**: Enable case-insensitive matching. When enabled, the pattern matches regardless of letter case (e.g., "EMAIL" matches "email", "Email", "EMAIL").
**Example: Email Detection**
```
Name: email_pattern
Target: Content
Patterns:
Name: "Standard Email"
Regex: [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}
Score: 0.9
Context: ["email", "e-mail", "contact"]
Confidence Threshold: 0.7
```
### Exact Terms Settings
The following fields appear when **Recognizer Type** is set to **Exact Term**:
* **Term List**: List of specific values to match against. The recognizer will identify data that exactly matches any value in this list. Useful for identifying specific sensitive terms, names, or identifiers that should be flagged. For example, \["confidential", "secret", "internal-only", "do-not-share"]
* **Supported Language**: Language scope for this recognizer. Defaults to **All**.
* **Regex Flags**: Toggle **Dot All**, **Multiline**, and **Ignore Case** as needed.
* **Dot All**: Enable dot-all regex flag. When enabled, the dot (.) metacharacter matches newline characters as well as any other character. Useful for multi-line pattern matching.
* **Multiline**: Enable multiline regex flag. When enabled, the ^ and \$ anchors match at line breaks in addition to the start and end of the entire string. Useful for patterns that should match line by line.
* **Ignore Case**: Enable case-insensitive matching. When enabled, the pattern matches regardless of letter case (e.g., "EMAIL" matches "email", "Email", "EMAIL").
**Example: Internal Codes**
```
Name: internal_dept_codes
Target: Content
Exact Terms:
- DEPT_001_CONFIDENTIAL
- DEPT_002_RESTRICTED
Ignore Case: true
Confidence Threshold: 0.9
```
### Predefined Recognizer Settings
The following fields appear when **Recognizer Type** is set to **Pre-Defined**:
* **Pre-Defined Recognizer**: Select a pre-configured recognizer from the system.
* **Financial**: AbaRoutingRecognizer, CreditCardRecognizer, IbanRecognizer, UsBankRecognizer
* **Personal ID**: UsSsnRecognizer, UsItinRecognizer, UsPassportRecognizer, UsLicenseRecognizer, InPanRecognizer, InAadhaarRecognizer
* **Healthcare**: NhsRecognizer, MedicalLicenseRecognizer, AuMedicareRecognizer
* **Contact**: EmailRecognizer, PhoneRecognizer, UrlRecognizer, IpRecognizer
* **Geographic**: EsNifRecognizer, EsNieRecognizer, UkNinoRecognizer, AuAbnRecognizer, PlPeselRecognizer
* **Advanced**: SpacyRecognizer, StanzaRecognizer, TransformersRecognizer, GLiNERRecognizer
* **Context** (optional): Context that helps boost the confidence score when found near detected entities. For example, for EmailRecognizer, context might include: "email", "contact", "address", "send".
* **Supported Language**: Language scope for this recognizer. Defaults to **All**.
**Example: SSN Detection**
```
Name: us_ssn_detector
Target: Content
Predefined Recognizer: UsSsnRecognizer
Context: ["SSN", "social", "security"]
Confidence Threshold: 0.8
```
### Column Name Recognizer Settings
When **Target** is set to **Column Name**, the recognizer matches against the column name itself rather than sampled row values. This is useful when sampled data is masked, anonymized, or unavailable.
Use **Exact Terms** type for known column names:
**Example: Tag columns named `email`, `person_id`, or `customer_email`**
```
Name: pii_column_name_detector
Target: Column Name
Type: Exact Terms
Exact Terms:
- email
- person_id
- customer_email
Ignore Case: true
Confidence Threshold: 1.0
```
Use **Pattern** type for column name conventions that follow a predictable format:
**Example: Tag any column ending in `_email` or `_id`**
```
Name: pii_column_pattern_detector
Target: Column Name
Type: Pattern
Patterns:
- Name: "Email columns"
Regex: .*_email$
Score: 1.0
- Name: "ID columns"
Regex: .*_id$
Score: 0.8
Confidence Threshold: 0.8
```
## Managing recognizers
### View all recognizers
The recognizers tab displays all recognizers for a tag with columns:
* **Enabled**: Toggle to activate/deactivate
* **Name** & **Description**
* **Type**: Pattern, Exact Terms, Predefined, or Context
* **Target**: Content or Column Name
* **Exceptions**: Number of entities excluded from this recognizer
* **Confidence**: Confidence threshold
### Filter & Search
Use filters to narrow the list:
* **Type**: Pattern, Exact Terms, Predefined, Context
* **Target**: Content, Column Name
* **Enabled**: Enabled, Disabled
Use the search box to find recognizers by name or description.
### Edit a Recognizer
1. Click **Edit** (pencil icon) in the Actions column
2. Modify fields in the form
3. Click **Save**
**Note**: Changes only apply to future classification runs, not retroactively.
### Delete a Recognizer
1. Click **Delete** (trash icon) in the Actions column
2. Confirm deletion
**Warning**: Deleting a recognizer does not remove tags it previously applied. You must manually remove those tags if needed.
### Enable/Disable recognizers
Use the toggle switch in the Enabled column to temporarily stop a recognizer without deleting it. Changes take effect on the next classification run.
### Managing Exceptions
Click the **Exceptions** count to view entities where this recognizer should not run. Exceptions are automatically added when [feedback is approved](/how-to-guides/data-governance/classification/auto-classification/feedback).
You can manually delete exceptions:
1. Click exceptions count
2. View list in the exceptions panel
3. Click delete on specific exceptions
4. Confirm removal
## Best Practices
### Creating effective recognizers
1. **Start with high confidence**: Begin with threshold 0.7-0.8, adjust if needed
2. **Test patterns first**: Validate regex patterns with sample data before creating the recognizer
3. **Use context words**: Add relevant context to reduce false positives
4. **Multiple patterns**: Create separate patterns for different formats (e.g., phone: `(123)456-7890` vs `123-456-7890`)
5. **Descriptive names**: Use clear, searchable names and descriptions
### Managing False Positives
1. **Review feedback regularly**: Check pending feedback from users
2. **Adjust thresholds**: If too many false positives, increase confidence threshold
3. **Refine patterns**: Edit patterns to be more specific
4. **Add context words**: Boost confidence for true positives with relevant context
### Performance Tips
1. **Target appropriately**: Use "Column Name" target when possible (faster than content analysis)
2. **Disable unused recognizers**: Deactivate recognizers you no longer need
3. **Combine patterns**: Use one recognizer with multiple patterns instead of many single-pattern recognizers
4. **Limit context words**: Keep context word lists concise (under 20 words)
## Troubleshooting
### Recognizer Not Detecting Data
**Check:**
* Recognizer is Enabled
* Confidence threshold not too high
* Pattern syntax is correct (test with a regex tool)
* Target matches your use case (Content vs Column Name)
* Entity is not in the exception list
* Profiler and auto-classification are enabled in ingestion config
### Too Many False Positives
**Solutions:**
* Increase confidence threshold
* Add context words for true positives
* Make patterns more specific
* Consider using exact terms recognizer instead
* Let users submit feedback to build exception lists
### Pattern Not Matching
**Common issues:**
* Missing escape characters in regex (use `\\d` not `\d`)
* Incorrect regex flags (check case sensitivity, multi-line)
* Pattern too specific or too broad
* Test your pattern at [regex101.com](https://regex101.com) first
## Next Steps
Learn how to report false positives and improve recognizer accuracy through user feedback
Understand the default PII tagging logic