> ## Documentation Index
> Fetch the complete documentation index at: https://docs.getcollate.io/llms.txt
> Use this file to discover all available pages before exploring further.
# OpenLineage Hybrid Runner | Collate Data Lineage Pipeline
> Connect your data pipelines with Collate's OpenLineage connector. Track data lineage, monitor pipeline metadata, and gain end-to-end visibility.
export const MetadataIngestionUi = ({connector, selectServicePath, addNewServicePath, serviceConnectionPath}) => {
return <>
To ingest metadata from your sources, you need to create a service connection.
The service connects your source system with Collate. Once you create
a service, you can use it to configure your ingestion workflows.
To create a service connection and ingest your metadata, follow the steps below:
-
On the left navigation bar, click Settings.
-
On the next page, click Services, and then select the service.
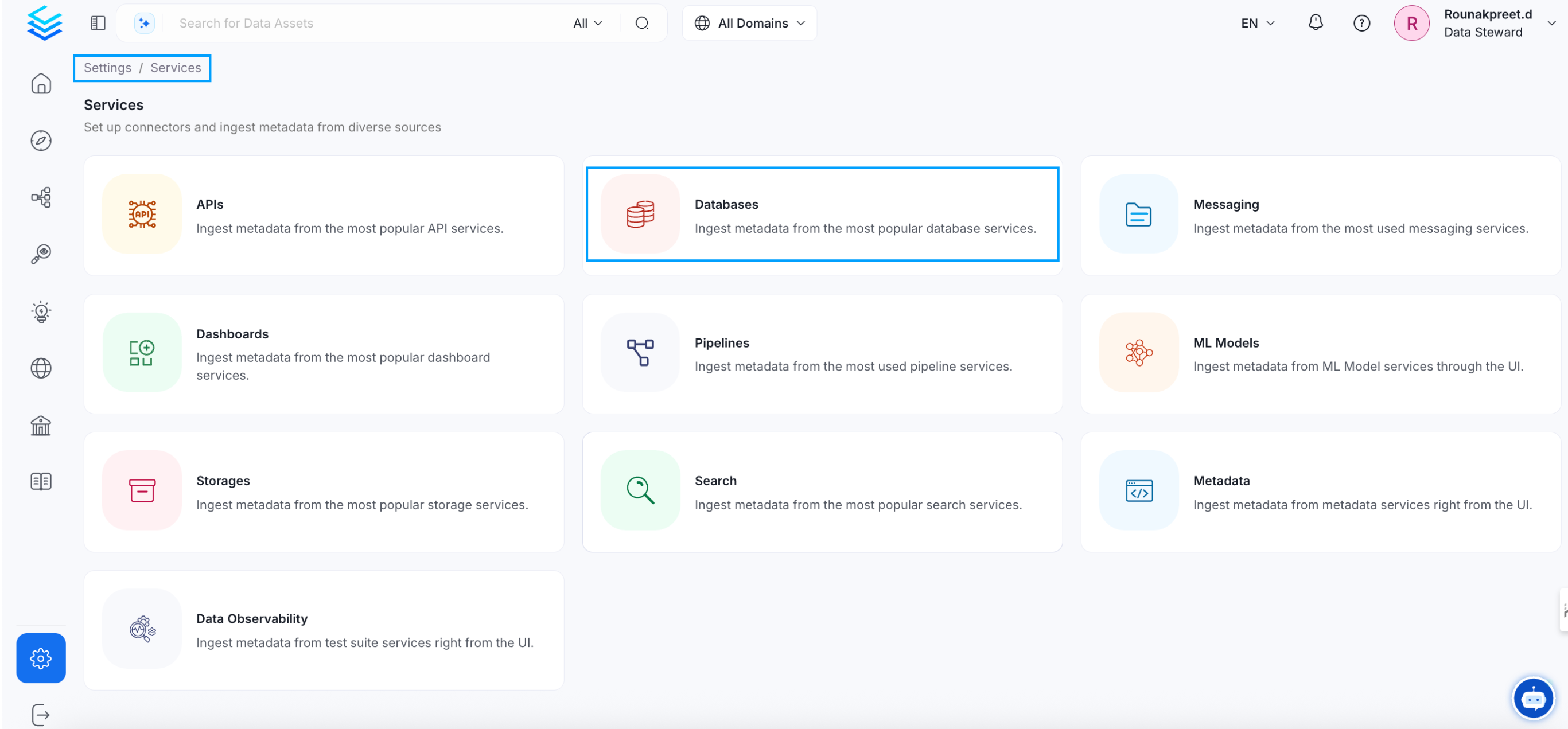
To add a new service connection, click Add New Service.
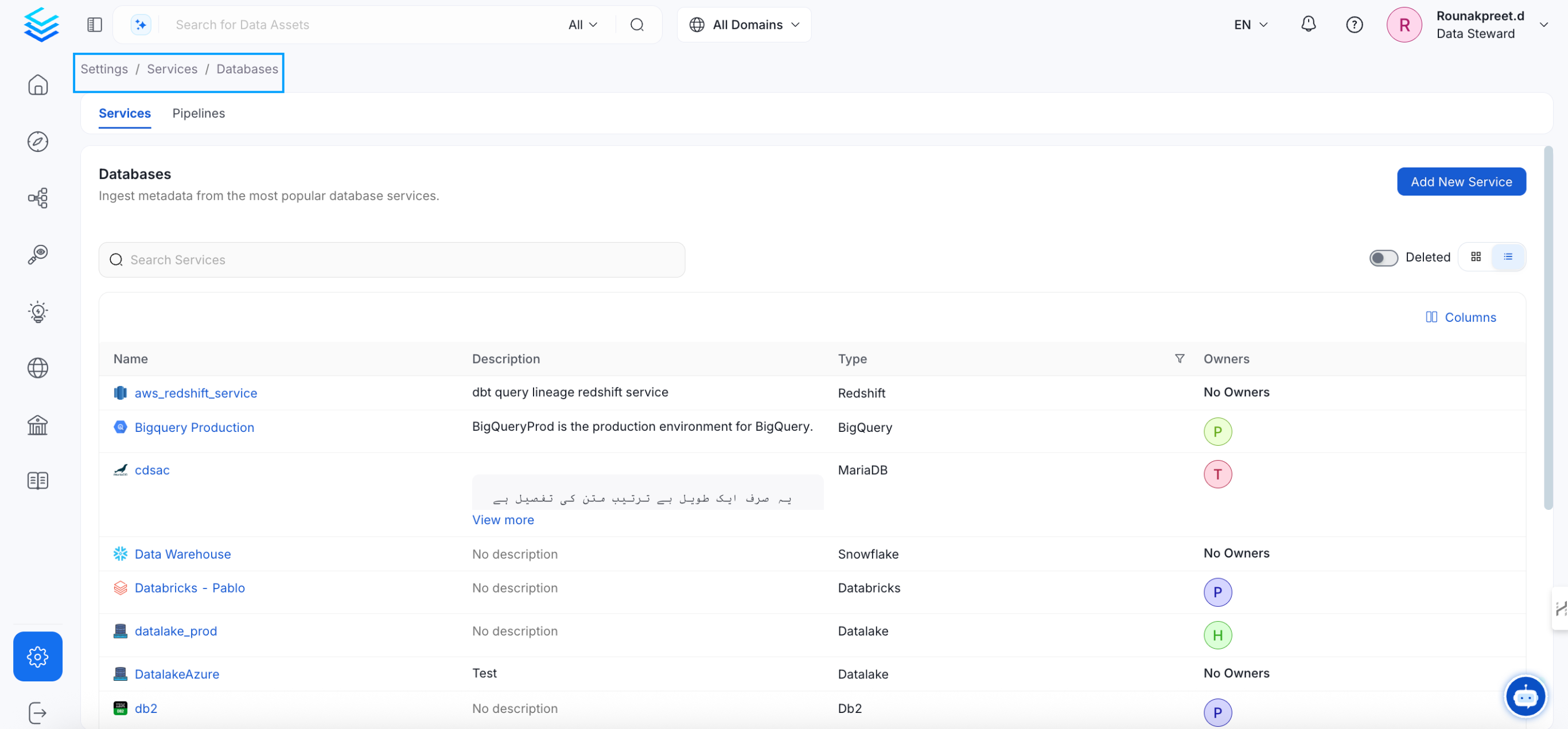 Select {connector} as the service type and click Next.
{selectServicePath &&
Select {connector} as the service type and click Next.
{selectServicePath &&  }
Enter a unique, descriptive Service Name and Description.
}
Enter a unique, descriptive Service Name and Description.
- Service Name: Collate identifies services by their service name. Enter a name that distinguishes this deployment from other services, including other {connector} services you are ingesting metadata from.
The service name cannot be changed after it is set.
{addNewServicePath &&  }
Set up the connection settings required for {connector}.
}
Set up the connection settings required for {connector}.
Configure the following connection options to set up the service and start ingesting metadata from your sources. The right-hand panel displays help documentation for the selected connection type in the product UI
{serviceConnectionPath &&  }
;
};
export const ConnectorDetailsHeader = ({name, icon, stage, availableFeatures, unavailableFeatures = [], availableFeaturesCollate = []}) => {
const showSubHeading = availableFeatures?.length > 0 || unavailableFeatures?.length > 0 || availableFeaturesCollate?.length > 0;
const totalAvailableFeatures = [...availableFeatures || [], ...availableFeaturesCollate || []];
return
}
;
};
export const ConnectorDetailsHeader = ({name, icon, stage, availableFeatures, unavailableFeatures = [], availableFeaturesCollate = []}) => {
const showSubHeading = availableFeatures?.length > 0 || unavailableFeatures?.length > 0 || availableFeaturesCollate?.length > 0;
const totalAvailableFeatures = [...availableFeatures || [], ...availableFeaturesCollate || []];
return
{icon &&
}
{name}
{stage}
{showSubHeading &&
Feature List
{totalAvailableFeatures.map(feature =>
✓ {feature}
)}
{unavailableFeatures.map(feature =>
✕ {feature}
)}
}
;
};
In this section, we provide guides and references to use the OpenLineage connector.
Configure and schedule OpenLineage metadata workflows from the Collate UI:
* [Requirements](#requirements)
* [Metadata Ingestion](#metadata-ingestion)
* [Troubleshooting](/connectors/pipeline/openlineage/troubleshooting)
## Requirements
Collate is integrated with OpenLineage up to version 1.37.0 and will continue to work for future OpenLineage versions.
OpenLineage is an open framework for data lineage collection and analysis. At its core is an extensible specification that systems can use to interoperate with lineage metadata.
Apart from being a specification, it is also a set of integrations collecting lineage from various systems such as Apache Airflow and Spark.
### Openlineage connector events
OpenLineage connector consumes open lineage events from kafka broker and translates it to Collate Lineage information.
1. #### Airflow OpenLineage events
To Configure your Airflow instance
1. To Configure your Airflow instance install appropriate provider in [Airflow](https://airflow.apache.org/docs/apache-airflow-providers-openlineage/stable/index.html)
2. Configure OpenLineage Provider in [Airflow](https://airflow.apache.org/docs/apache-airflow-providers-openlineage/stable/guides/user.html#using-openlineage-integration)
* Remember to use `kafka` transport mode here as OL events are collected from kafka topic. Detailed list of configuration options for OpenLineage can be found [here](https://openlineage.io/docs/client/python/#configuration)
3. #### Spark OpenLineage events
Configure Spark Session to produce OpenLineage events compatible with OpenLineage connector available in Collate. complete the kafka config using the below code.
```shell theme={null}
from pyspark.sql import SparkSession
from uuid import uuid4
spark = SparkSession.builder\
.config('spark.openlineage.namespace', 'mynamespace')\
.config('spark.openlineage.parentJobName', 'hello-world')\
.config('spark.openlineage.parentRunId', str(uuid4()))\
.config('spark.jars.packages', 'io.openlineage:openlineage-spark_2.12:1.37.0')\
.config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener')\
.config('spark.openlineage.transport.type', 'kafka')\
.getOrCreate()
```
## Metadata Ingestion
## Connection Details
Once the credentials have been added, click on *Test Connection* and *Save* the changes.
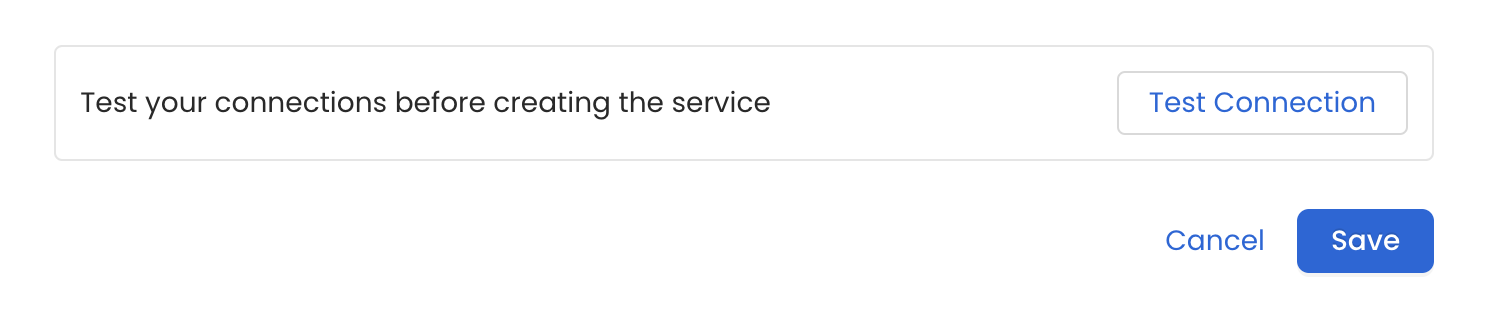 In this step we will configure the metadata ingestion pipeline,
Please follow the instructions below
In this step we will configure the metadata ingestion pipeline,
Please follow the instructions below
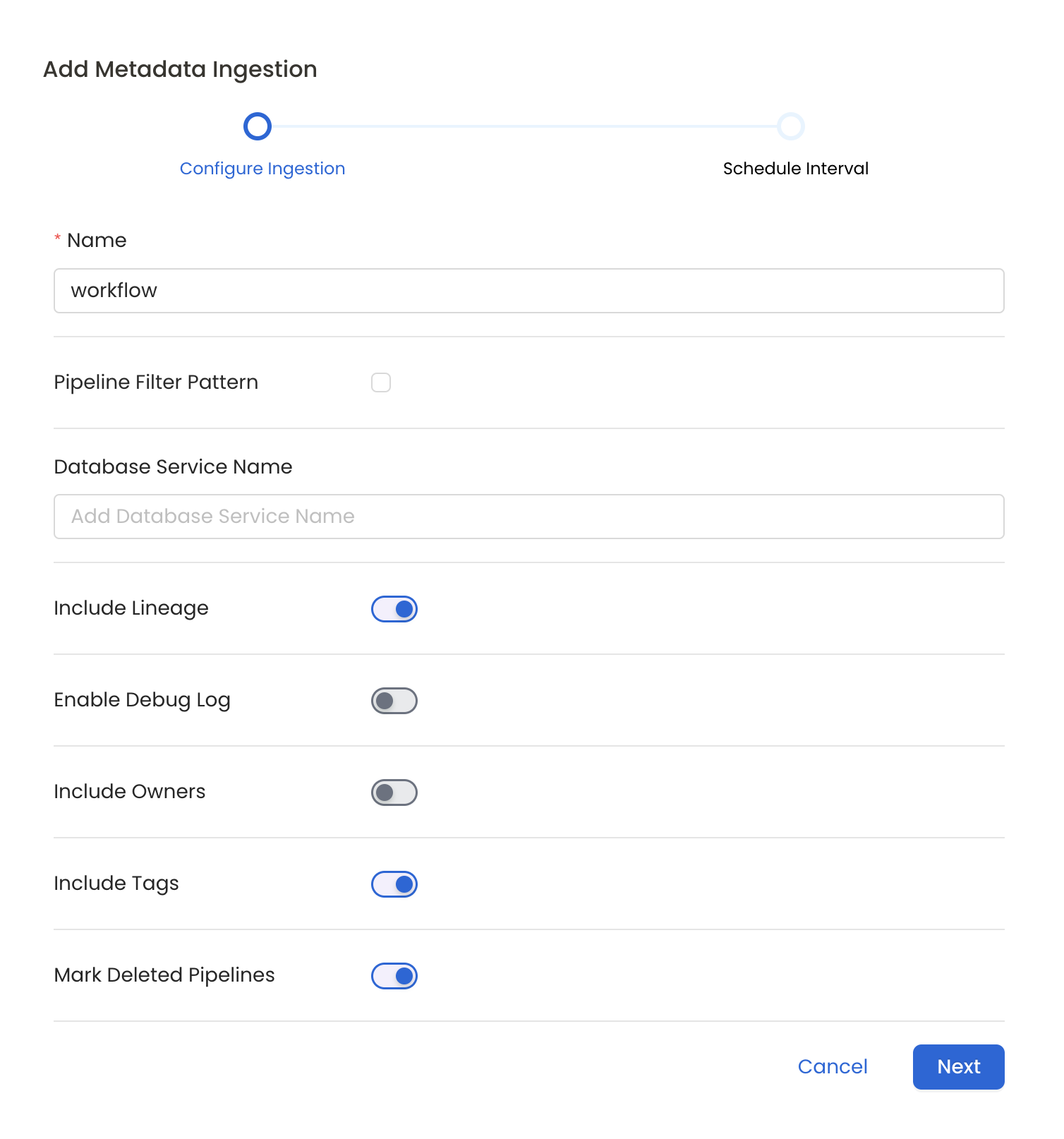 #### Metadata Ingestion Options
* **Name**: This field refers to the name of ingestion pipeline, you can customize the name or use the generated name.
* **Pipeline Filter Pattern (Optional)**: Use to pipeline filter patterns to control whether or not to include pipeline as part of metadata ingestion.
* **Include**: Explicitly include pipeline by adding a list of comma-separated regular expressions to the Include field. OpenMetadata will include all pipeline with names matching one or more of the supplied regular expressions. All other schemas will be excluded.
* **Exclude**: Explicitly exclude pipeline by adding a list of comma-separated regular expressions to the Exclude field. OpenMetadata will exclude all pipeline with names matching one or more of the supplied regular expressions. All other schemas will be included.
* **Include lineage (toggle)**: Set the Include lineage toggle to control whether to include lineage between pipelines and data sources as part of metadata ingestion.
* **Enable Debug Log (toggle)**: Set the Enable Debug Log toggle to set the default log level to debug.
* **Mark Deleted Pipelines (toggle)**: Set the Mark Deleted Pipelines toggle to flag pipelines as soft-deleted if they are not present anymore in the source system.
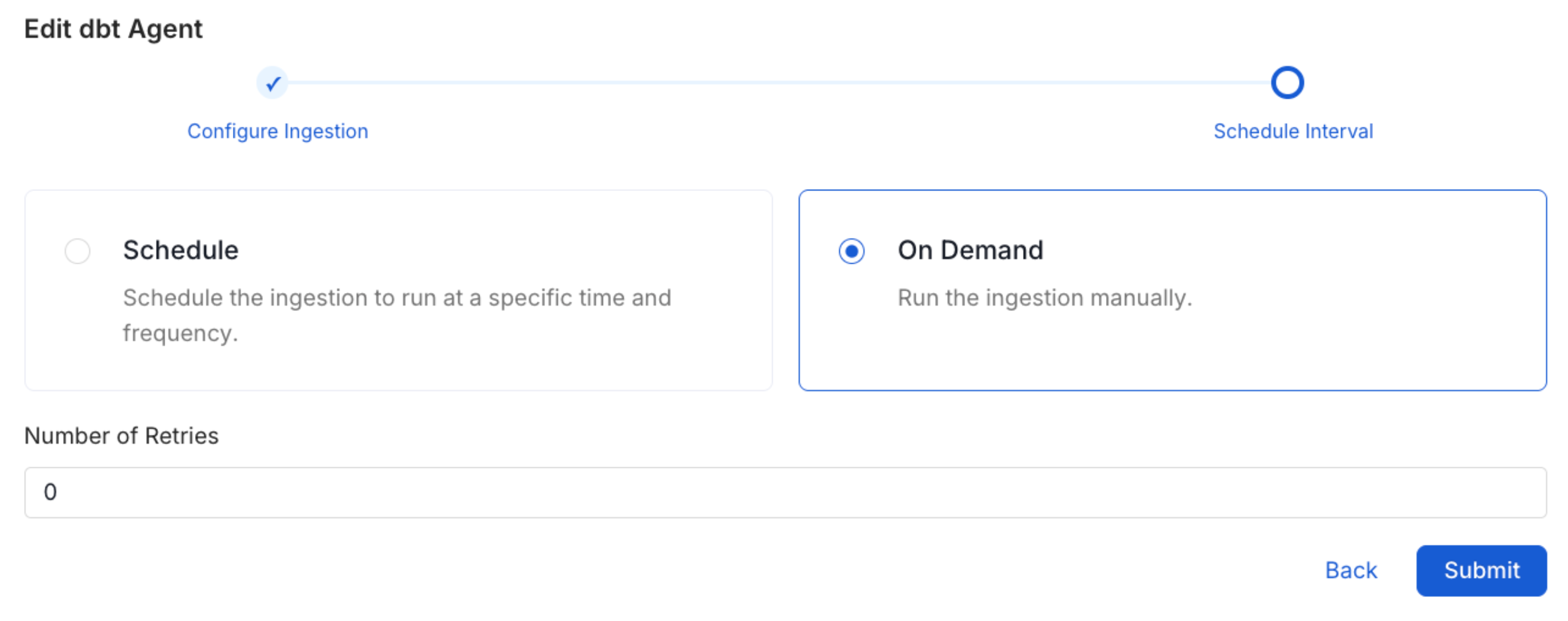
Scheduling can be set up at an hourly, daily, weekly, or manual cadence. The
timezone is in UTC. Select a Start Date to schedule for ingestion. It is
optional to add an End Date.
Review your configuration settings. If they match what you intended,
click Deploy to create the service and schedule metadata ingestion.
If something doesn't look right, click the Back button to return to the
appropriate step and change the settings as needed.
After configuring the workflow, you can click on Deploy to create the
pipeline.
#### Metadata Ingestion Options
* **Name**: This field refers to the name of ingestion pipeline, you can customize the name or use the generated name.
* **Pipeline Filter Pattern (Optional)**: Use to pipeline filter patterns to control whether or not to include pipeline as part of metadata ingestion.
* **Include**: Explicitly include pipeline by adding a list of comma-separated regular expressions to the Include field. OpenMetadata will include all pipeline with names matching one or more of the supplied regular expressions. All other schemas will be excluded.
* **Exclude**: Explicitly exclude pipeline by adding a list of comma-separated regular expressions to the Exclude field. OpenMetadata will exclude all pipeline with names matching one or more of the supplied regular expressions. All other schemas will be included.
* **Include lineage (toggle)**: Set the Include lineage toggle to control whether to include lineage between pipelines and data sources as part of metadata ingestion.
* **Enable Debug Log (toggle)**: Set the Enable Debug Log toggle to set the default log level to debug.
* **Mark Deleted Pipelines (toggle)**: Set the Mark Deleted Pipelines toggle to flag pipelines as soft-deleted if they are not present anymore in the source system.
Scheduling can be set up at an hourly, daily, weekly, or manual cadence. The
timezone is in UTC. Select a Start Date to schedule for ingestion. It is
optional to add an End Date.
Review your configuration settings. If they match what you intended,
click Deploy to create the service and schedule metadata ingestion.
If something doesn't look right, click the Back button to return to the
appropriate step and change the settings as needed.
After configuring the workflow, you can click on Deploy to create the
pipeline.
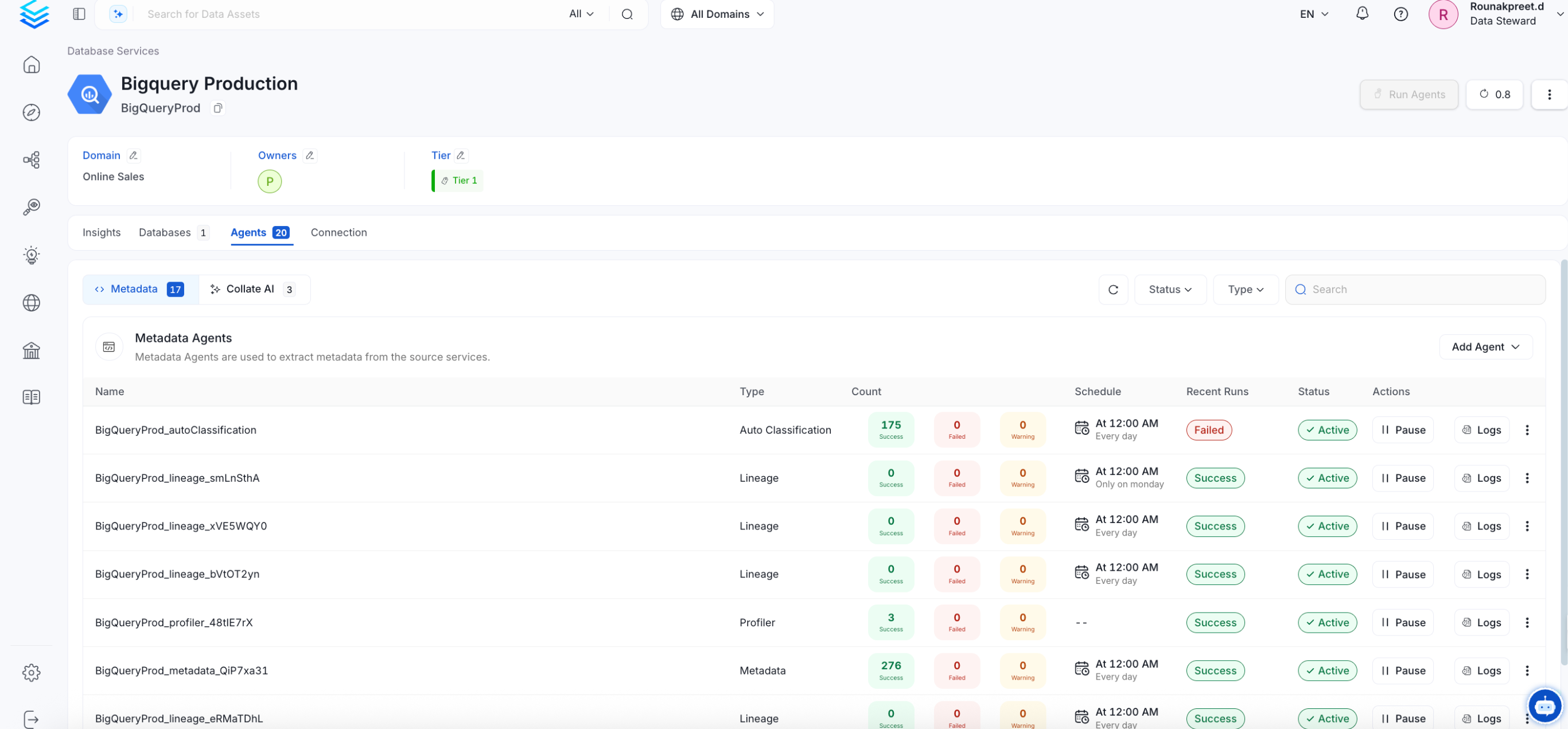
 Once the workflow has been successfully deployed, you can view the
Ingestion Pipeline running from the Service Page.
Once the workflow has been successfully deployed, you can view the
Ingestion Pipeline running from the Service Page.
 If [AutoPilot](/how-to-guides/admin-guide/applications/autopilot) is enabled, workflows like usage tracking, data lineage, and similar tasks will be handled automatically. Users don’t need to set up or manage them - AutoPilot takes care of everything in the system.
### Providing connection details programmatically via API
#### 1. Preparing the Client
```python theme={null}
from metadata.sdk import configure
configure(
host="http://localhost:8585/api",
jwt_token="",
)
```
#### 2. Creating the OpenLineage Pipeline service
```python theme={null}
from metadata.generated.schema.api.services.createPipelineService import CreatePipelineServiceRequest
from metadata.generated.schema.entity.services.pipelineService import (
PipelineServiceType,
PipelineConnection,
)
from metadata.generated.schema.entity.services.connections.pipeline.openLineageConnection import (
OpenLineageConnection,
SecurityProtocol as KafkaSecurityProtocol,
ConsumerOffsets
)
from metadata.generated.schema.security.ssl.validateSSLClientConfig import (
ValidateSslClientConfig,
)
openlineage_service_request = CreatePipelineServiceRequest(
name='openlineage-service',
displayName='OpenLineage Service',
serviceType=PipelineServiceType.OpenLineage,
connection=PipelineConnection(
config=OpenLineageConnection(
brokersUrl='broker1:9092,broker2:9092',
topicName='openlineage-events',
consumerGroupName='openmetadata-consumer',
consumerOffsets=ConsumerOffsets.earliest,
poolTimeout=3.0,
sessionTimeout=60,
securityProtocol=KafkaSecurityProtocol.SSL,
# below ssl config is optional and used only when securityProtocol=KafkaSecurityProtocol.SSL
sslConfig=ValidateSslClientConfig(
sslCertificate='/path/to/kafka/certs/Certificate.pem',
sslKey='/path/to/kafka/certs/Key.pem',
caCertificate='/path/to/kafka/certs/RootCA.pem'
)
)
),
)
# Pending fluent API: PipelineServices.create(openlineage_service_request)
```
When using a **Hybrid Ingestion Runner**, any sensitive credential fields—such as passwords, API keys, or private keys—must reference secrets using the following format:
```
password: secret:/my/database/password
```
This applies **only to fields marked as secrets** in the connection form (these typically mask input and show a visibility toggle icon).
For a complete guide on managing secrets in hybrid setups, see the [Hybrid Ingestion Runner Secret Management Guide](https://docs.getcollate.io/getting-started/day-1/hybrid-saas/hybrid-ingestion-runner#3.-manage-secrets-securely).
## Troubleshooting
Learn more about how to troubleshoot common OpenLineage connector issues and resolve configuration or ingestion errors.
If [AutoPilot](/how-to-guides/admin-guide/applications/autopilot) is enabled, workflows like usage tracking, data lineage, and similar tasks will be handled automatically. Users don’t need to set up or manage them - AutoPilot takes care of everything in the system.
### Providing connection details programmatically via API
#### 1. Preparing the Client
```python theme={null}
from metadata.sdk import configure
configure(
host="http://localhost:8585/api",
jwt_token="",
)
```
#### 2. Creating the OpenLineage Pipeline service
```python theme={null}
from metadata.generated.schema.api.services.createPipelineService import CreatePipelineServiceRequest
from metadata.generated.schema.entity.services.pipelineService import (
PipelineServiceType,
PipelineConnection,
)
from metadata.generated.schema.entity.services.connections.pipeline.openLineageConnection import (
OpenLineageConnection,
SecurityProtocol as KafkaSecurityProtocol,
ConsumerOffsets
)
from metadata.generated.schema.security.ssl.validateSSLClientConfig import (
ValidateSslClientConfig,
)
openlineage_service_request = CreatePipelineServiceRequest(
name='openlineage-service',
displayName='OpenLineage Service',
serviceType=PipelineServiceType.OpenLineage,
connection=PipelineConnection(
config=OpenLineageConnection(
brokersUrl='broker1:9092,broker2:9092',
topicName='openlineage-events',
consumerGroupName='openmetadata-consumer',
consumerOffsets=ConsumerOffsets.earliest,
poolTimeout=3.0,
sessionTimeout=60,
securityProtocol=KafkaSecurityProtocol.SSL,
# below ssl config is optional and used only when securityProtocol=KafkaSecurityProtocol.SSL
sslConfig=ValidateSslClientConfig(
sslCertificate='/path/to/kafka/certs/Certificate.pem',
sslKey='/path/to/kafka/certs/Key.pem',
caCertificate='/path/to/kafka/certs/RootCA.pem'
)
)
),
)
# Pending fluent API: PipelineServices.create(openlineage_service_request)
```
When using a **Hybrid Ingestion Runner**, any sensitive credential fields—such as passwords, API keys, or private keys—must reference secrets using the following format:
```
password: secret:/my/database/password
```
This applies **only to fields marked as secrets** in the connection form (these typically mask input and show a visibility toggle icon).
For a complete guide on managing secrets in hybrid setups, see the [Hybrid Ingestion Runner Secret Management Guide](https://docs.getcollate.io/getting-started/day-1/hybrid-saas/hybrid-ingestion-runner#3.-manage-secrets-securely).
## Troubleshooting
Learn more about how to troubleshoot common OpenLineage connector issues and resolve configuration or ingestion errors.